What, why?
This is a collection of various blog posts I've transcribed. The reason I am bothering is
- Its really common for blogs to go unmaintained and then poof i've lost that info.
- I can start to organize and search over stuff better this way. No more "oh, what was that random blog from 10 years ago that talked about this thing?" for me.
I haven't and won't transcribe each and every link in the posts, so some references might become dead, but I am going to do my best to make this useful on its own.
In progress
Links I still need to do
- https://web.archive.org/web/20200423065845/https://blog.reactioncommerce.com/how-to-implement-graphql-pagination-and-sorting/
- https://tomassetti.me/antlr-mega-tutorial/
- https://mattferraro.dev/posts/poissons-equation
- https://libertysys.com.au/2016/09/the-school-for-sysadmins-who-cant-timesync-good-and-wanna-learn-to-do-other-stuff-good-too-part-1-the-problem-with-ntp/
- https://blog.crunchydata.com/blog/better-json-in-postgres-with-postgresql-14
- https://javahippie.net/clojure/apm/2021/05/29/tracing-with-alter-var-root.html
- https://www.toptal.com/java/how-hibernate-ruined-my-career
- https://www.sorcerers-tower.net/articles/configuring-jetty-for-https-with-letsencrypt
- https://quarkus.io/version/1.7/guides/optaplanner
- https://reactnative.dev/docs/testing-overview
- https://antonz.org/python-packaging/
- https://jessewarden.com/2018/06/functional-programming-unit-testing-in-node-part-1.html
- https://malloc.se/blog/zgc-jdk16
- https://gigasquidsoftware.com/blog/2021/03/15/breakfast-with-zero-shot-nlp/
- https://beepb00p.xyz/sad-infra.html#why_search
- https://www.infoworld.com/article/2074186/j2ee-or-j2se--jndi-works-with-both.html
- https://trenki2.github.io/blog/2017/06/02/using-sdl2-with-cmake/
- https://blog.discord.com/why-discord-is-switching-from-go-to-rust-a190bbca2b1f
- https://suade.org/dev/12-requests-per-second-with-python/
- https://rustyyato.github.io/type/system,type/families/2021/02/15/Type-Families-1.html
- https://tanelpoder.com/posts/reasons-why-select-star-is-bad-for-sql-performance/
- https://www.compose.com/articles/postgresql-tips-documenting-the-database/
- https://chriskiehl.com/article/thoughts-after-6-years
- https://www.marcolancini.it/offensive-infrastructure/
- https://dashbit.co/blog/you-may-not-need-redis-with-elixir
- https://www.imperva.com/learn/performance/cache-control/
- https://www.smashingmagazine.com/2016/09/the-thumb-zone-designing-for-mobile-users/
- https://codahale.com/how-to-safely-store-a-password/
- https://vmlens.com/articles/cp/4_atomic_updates/
- https://tomcam.github.io/postgres/
- https://wozniak.ca/blog/2014/08/03/1/
- https://blog.brunobonacci.com/2014/11/16/clojure-complete-guide-to-destructuring/
- https://www.teamten.com/lawrence/programming/use-singular-nouns-for-database-table-names.html
- http://highscalability.com/blog/2014/9/8/how-twitter-uses-redis-to-scale-105tb-ram-39mm-qps-10000-ins.html
- https://cran.r-project.org/web/packages/viridis/vignettes/intro-to-viridis.html
- https://acoup.blog/2020/09/18/collections-iron-how-did-they-make-it-part-i-mining/
- https://inside.java/2020/08/07/loom-performance/
- https://cssfordesigners.com/articles/things-i-wish-id-known-about-css
- https://alexwlchan.net/2018/01/downloading-sqs-queues/
- https://web.archive.org/web/20201031072102/https://akshayr.me/blog/articles/python-dictionaries
- https://abramov.io/rust-dropping-things-in-another-thread
- https://blog.kevmod.com/2020/05/python-performance-its-not-just-the-interpreter/
- https://medium.com/teamzerolabs/5-aws-services-you-should-avoid-f45111cc10cd
- https://www.phoenixframework.org/blog/build-a-real-time-twitter-clone-in-15-minutes-with-live-view-and-phoenix-1-5
- https://grahamc.com/blog/erase-your-darlings
- https://www.alibabacloud.com/blog/how-to-deploy-apps-effortlessly-with-packer-and-terraform_593894
- https://vlaaad.github.io/year-of-clojure-on-the-desktop
- https://fasterthanli.me/articles/i-want-off-mr-golangs-wild-ride
- https://www.forrestthewoods.com/blog/memory-bandwidth-napkin-math/
- https://m.signalvnoise.com/only-15-of-the-basecamp-operations-budget-is-spent-on-ruby/
- https://www.mattlayman.com/blog/2019/failed-saas-postmortem
- https://sujithjay.com/data-systems/dynamo-cassandra/
- http://gustavlundin.com/di-frameworks-are-dynamic-binding/
- https://evilmartians.com/chronicles/graphql-on-rails-1-from-zero-to-the-first-query
- https://medium.com/@cep21/after-using-both-i-regretted-switching-from-terraform-to-cloudformation-8a6b043ad97a
- https://jvns.ca/blog/2019/10/03/sql-queries-don-t-start-with-select/
- https://vas3k.com/blog/computational_photography/
- https://blog.pragmaticengineer.com/software-architecture-is-overrated/
- https://web.archive.org/web/20190323123400/https://codahale.com/downloads/email-to-donald.txt
- https://www.dynamodbguide.com/the-dynamo-paper
- https://blog.sulami.xyz/posts/why-i-like-clojure/
- https://medium.com/javascript-scene/mocking-is-a-code-smell-944a70c90a6a
- https://medium.com/airbnb-engineering/sunsetting-react-native-1868ba28e30a
- https://dropbox.tech/mobile/the-not-so-hidden-cost-of-sharing-code-between-ios-and-android
- https://phoboslab.org/log/2019/06/pl-mpeg-single-file-library
- http://cachestocaches.com/2019/8/myths-list-antipattern/
- https://code.thheller.com/blog/shadow-cljs/2018/06/15/why-not-webpack.html
- https://snow-dev.com/posts/ecs-cd-with-codepipeline-in-terraform.html
- https://www.cloudbees.com/blog/terraforming-your-docker-environment-on-aws
- https://blog.danslimmon.com/2019/07/15/do-nothing-scripting-the-key-to-gradual-automation/
- https://blog.gruntwork.io/an-introduction-to-terraform-f17df9c6d180
- https://boats.gitlab.io/blog/post/notes-on-a-smaller-rust/
- https://medium.com/@thi.ng/how-to-ui-in-2018-ac2ae02acdf3
- https://jessicagreben.medium.com/how-to-terraform-locking-state-in-s3-2dc9a5665cb6
- https://ferd.ca/ten-years-of-erlang.html
- https://paulhammant.com/2013/03/28/interface-builders-alternative-lisp-timeline/
- http://blog.pnkfx.org/blog/2019/06/26/breaking-news-non-lexical-lifetimes-arrives-for-everyone/
- https://itnext.io/updating-an-sql-database-schema-using-node-js-6c58173a455a
- https://web.archive.org/web/20210218084259/https://expeditedsecurity.com/aws-in-plain-english/
- https://datawhatnow.com/things-you-are-probably-not-using-in-python-3-but-should/
- http://blogs.tedneward.com/post/the-vietnam-of-computer-science/
- https://vorpus.org/blog/why-im-not-collaborating-with-kenneth-reitz/
- https://yourlabs.org/posts/2019-04-19-storing-hd-photos-in-a-relational-database-recipe-for-an-epic-fail/
- https://slack.engineering/evolving-api-pagination-at-slack/
- https://matthewrayfield.com/articles/animating-urls-with-javascript-and-emojis/#%F0%9F%8C%95%F0%9F%8C%95%F0%9F%8C%95%F0%9F%8C%95%F0%9F%8C%95%F0%9F%8C%95%F0%9F%8C%95%F0%9F%8C%98%F0%9F%8C%91%F0%9F%8C%9101:22%E2%95%B101:50
- http://www.beyondthelines.net/databases/dynamodb-vs-cassandra/
- https://blog.bloomca.me/2019/02/23/alternatives-to-jsx.html
- https://iamturns.com/typescript-babel/
- https://blog.haschek.at/2018/the-curious-case-of-the-RasPi-in-our-network.html
- https://jrheard.tumblr.com/post/43575891007/explorations-in-clojures-corelogic
- https://www.theguardian.com/info/2018/nov/30/bye-bye-mongo-hello-postgres
- https://www.cloudbees.com/blog/tuning-nginx
- https://blogs.oracle.com/javamagazine/java-builder-pattern-bloch?source=:so:tw:or:awr:jav:::&SC=:so:tw:or:awr:jav:::&pcode=
- https://www.kode-krunch.com/2021/07/hibernate-traps-transactional.html
- https://www.kode-krunch.com/2021/06/hibernate-traps-leaky-abstraction.html
- https://www.kode-krunch.com/2021/05/storing-read-optimized-trees-in.html
- https://www.kode-krunch.com/2021/05/creating-simple-yet-powerful-expression.html
- https://www.kode-krunch.com/2021/05/dealing-with-springs-reactive-webclient.html
- https://chriswarrick.com/blog/2018/07/17/pipenv-promises-a-lot-delivers-very-little/#
- https://blog.cleancoder.com/uncle-bob/2016/05/01/TypeWars.html
- https://paulhammant.com/2013/02/04/the-importance-of-the-dom
- https://adambard.com/blog/easy-auth-with-friend/
- https://madattheinternet.com/2021/07/08/where-the-sidewalk-ends-the-death-of-the-internet/
- https://blog.discourse.org/2021/07/faster-user-uploads-on-discourse-with-rust-webassembly-and-mozjpeg
- https://www.notamonadtutorial.com/clojerl-an-implementation-of-the-clojure-language-that-runs-on-the-beam/
- https://trekhleb.dev/blog/2021/binary-floating-point/
- https://www.juxt.pro/blog/maven-central
- https://www.juxt.pro/blog/bitemporality-more-than-a-design-pattern
- https://www.juxt.pro/blog/json-in-clojure
- https://opencrux.com/main/index.html
- https://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/
- https://martintrojer.github.io/clojure/2013/07/07/coreasync-and-blocking-io
- https://blog.frankel.ch/start-rust/7/
- https://adambard.com/blog/easy-auth-with-friend/
- https://crisal.io/words/2020/02/28/C++-rust-ffi-patterns-1-complex-data-structures.html
- https://www.pixelstech.net/article/1582964859-How-many-bytes-a-boolean-value-takes-in-Java
- http://www.johngustafson.net/pdfs/BeatingFloatingPoint.pdf
- https://erlang.org/download/armstrong_thesis_2003.pdf
- https://bien.ee/a-contenteditable-pasted-garbage-and-caret-placement-walk-into-a-pub/
- https://corfield.org/blog/2021/07/21/deps-edn-monorepo-4/
- https://world.hey.com/dhh/modern-web-apps-without-javascript-bundling-or-transpiling-a20f2755
- https://stegosaurusdormant.com/understanding-derive-clone/
- https://www.2ndquadrant.com/en/blog/postgresql-anti-patterns-unnecessary-jsonhstore-dynamic-columns/
- https://opencrux.com/blog/crux-strength-of-the-record.html
- https://tenthousandmeters.com/blog/python-behind-the-scenes-12-how-asyncawait-works-in-python/
- https://www.infoq.com/presentations/Impedance-Mismatch/
- https://albertnetymk.github.io/2021/08/03/template_interpreter/
https://lukeplant.me.uk/blog/posts/yagni-exceptions/
YAGNI exceptions
by Luke Plant Posted in: Software development — June 29, 2021 at 09:42
I’m essentially a believer in You Aren’t Gonna Need It — the principle that you should add features to your software — including generality and abstraction — when it becomes clear that you need them, and not before.
However, there are some things which really are easier to do earlier than later, and where natural tendencies or a ruthless application of YAGNI might neglect them. This is my collection so far:
-
Applications of Zero One Many. If the requirements go from saying “we need to be able to store an address for each user”, to “we need to be able to store two addresses for each user”, 9 times out of 10 you should go straight to “we can store many addresses for each user”, with a soft limit of two for the user interface only, because there is a very high chance you will need more than two. You will almost certainly win significantly by making that assumption, and even if you lose it won’t be by much.
-
Versioning. This can apply to protocols, APIs, file formats etc. It is good to think about how, for example, a client/server system will detect and respond to different versions ahead of time (i.e. even when there is only one version), especially when you don’t control both ends or can’t change them together, because it is too late to think about this when you find you need a version 2 after all. This is really an application of Embrace Change, which is a principle at the heart of YAGNI.
-
Logging. Especially for after-the-fact debugging, and in non-deterministic or hard to reproduce situations, where it is often too late to add it after you become aware of a problem.
-
Timestamps.
For example, creation timestamps, as Simon Willison tweeted:
A lesson I re-learn on every project: always have an automatically populated “created_at” column on every single database table. Any time you think “I won’t need it here” you’re guaranteed to want to use it for debugging something a few weeks later.
More generally, instead of a boolean flag, e.g. completed, a nullable timestamp of when the state was entered, completed_at, can be much more useful.
-
Generalising from the “logging” and “timestamps” points, collecting a bit more data than you need right now is usually not a problem (unless it is personal or otherwise sensitive data), because you can always throw it away. But if you never collected it, it’s gone forever. I have won significantly when I’ve anticipated the need for auditing which wasn’t completely explicit in the requirements, and I’ve lost significantly when I’ve gone for data minimalism which lost key information and limited what I could do with the data later.
-
A relational database.
By this I mean, if you need a database at all, you should jump to having a relational one straight away, and default to a relational schema, even if your earliest set of requirements could be served by a “document database” or some basic flat-file system. Most data is relational by nature, and a non-relational database is a very bad default for almost all applications.
If you choose a relational database like PostgreSQL, and it later turns out a lot of your data is “document like”, you can use its excellent support for JSON.
However, if you choose a non-rel DB like MongoDB, even when it seems like you’ve got a perfect fit in terms of current schema needs, most likely a new, “simple” requirement will cause you a lot of pain, and prompt a rewrite in Postgres (see sections “How MongoDB Stores Data” and “Epilogue” in that article).
I thought a comment on Lobsters I read the other day was insightful here:
I wonder if the reason that “don’t plan, don’t abstract, don’t engineer for the future” is such good advice is that most people are already building on top of highly-abstracted and featureful platforms, which don’t need to be abstracted further?
We can afford to do YAGNI only when the systems we are working with are malleable and featureful. Relational databases are extremely flexible systems that provide insurance against future requirements changes. For example, my advice in the previous section implicitly depends on the fact that removing data you don’t need can be as simple as “DROP COLUMN”, which is almost free (well, sometimes…).
That’s my list so far, I’ll probably add to it over time. Do you agree? What did I miss?
Links
Discussion of this post on Twitter
Commit messages guide
What is a "commit"?
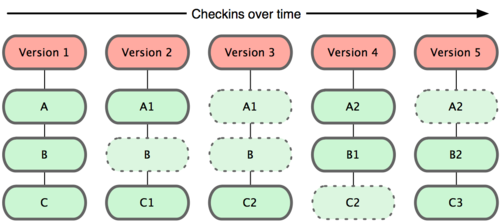
In simple terms, a commit is a snapshot of your local files, written in your local repository. Contrary to what some people think, git doesn't store only the difference between the files, it stores a full version of all files. For files that didn't change from one commit to another, git stores just a link to the previous identical file that is already stored.
The image below shows how git stores data over time, in which each "Version" is a commit:
Why are commit messages important?
- To speed up and streamline code reviews
- To help in the understanding of a change
- To explain "the whys" that cannot be described only with code
- To help future maintainers figure out why and how changes were made, making troubleshooting and debugging easier
To maximize those outcomes, we can use some good practices and standards described in the next section.
Good practices
These are some practices collected from my experiences, internet articles, and other guides. If you have others (or disagree with some) feel free to open a Pull Request and contribute.
Use imperative form
# Good
Use InventoryBackendPool to retrieve inventory backend
# Bad
Used InventoryBackendPool to retrieve inventory backend
But why use the imperative form?
A commit message describes what the referenced change actually does, its effects, not what was done.
This excellent article from Chris Beams gives us a simple sentence that can be used to help us write better commit messages in imperative form:
If applied, this commit will <commit message>
Examples:
# Good
If applied, this commit will use InventoryBackendPool to retrieve inventory backend
# Bad
If applied, this commit will used InventoryBackendPool to retrieve inventory backend
Capitalize the first letter
# Good
Add `use` method to Credit model
# Bad
add `use` method to Credit model
The reason that the first letter should be capitalized is to follow the grammar rule of using capital letters at the beginning of sentences.
The use of this practice may vary from person to person, team to team, or even from language to language. Capitalized or not, an important point is to stick to a single standard and follow it.
Try to communicate what the change does without having to look at the source code
# Good
Add `use` method to Credit model
# Bad
Add `use` method
# Good
Increase left padding between textbox and layout frame
# Bad
Adjust css
It is useful in many scenarios (e.g. multiple commits, several changes and refactors) to help reviewers understand what the committer was thinking.
Use the message body to explain "why", "for what", "how" and additional details
# Good
Fix method name of InventoryBackend child classes
Classes derived from InventoryBackend were not
respecting the base class interface.
It worked because the cart was calling the backend implementation
incorrectly.
# Good
Serialize and deserialize credits to json in Cart
Convert the Credit instances to dict for two main reasons:
- Pickle relies on file path for classes and we do not want to break up
everything if a refactor is needed
- Dict and built-in types are pickleable by default
# Good
Add `use` method to Credit
Change from namedtuple to class because we need to
setup a new attribute (in_use_amount) with a new value
The subject and the body of the messages are separated by a blank line. Additional blank lines are considered as a part of the message body.
Characters like -, * and ` are elements that improve readability.
Avoid generic messages or messages without any context
# Bad
Fix this
Fix stuff
It should work now
Change stuff
Adjust css
Limit the number of characters
It's recommended to use a maximum of 50 characters for the subject and 72 for the body.
Keep language consistency
For project owners: Choose a language and write all commit messages using that language. Ideally, it should match the code comments, default translation locale (for localized projects), etc.
For contributors: Write your commit messages using the same language as the existing commit history.
# Good
ababab Add `use` method to Credit model
efefef Use InventoryBackendPool to retrieve inventory backend
bebebe Fix method name of InventoryBackend child classes
# Good (Portuguese example)
ababab Adiciona o método `use` ao model Credit
efefef Usa o InventoryBackendPool para recuperar o backend de estoque
bebebe Corrige nome de método na classe InventoryBackend
# Bad (mixes English and Portuguese)
ababab Usa o InventoryBackendPool para recuperar o backend de estoque
efefef Add `use` method to Credit model
cdcdcd Agora vai
Template
This is a template, written originally by Tim Pope, which appears in the Pro Git Book.
Summarize changes in around 50 characters or less
More detailed explanatory text, if necessary. Wrap it to about 72
characters or so. In some contexts, the first line is treated as the
subject of the commit and the rest of the text as the body. The
blank line separating the summary from the body is critical (unless
you omit the body entirely); various tools like `log`, `shortlog`
and `rebase` can get confused if you run the two together.
Explain the problem that this commit is solving. Focus on why you
are making this change as opposed to how (the code explains that).
Are there side effects or other unintuitive consequences of this
change? Here's the place to explain them.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, preceded
by a single space, with blank lines in between, but conventions
vary here
If you use an issue tracker, put references to them at the bottom,
like this:
Resolves: #123
See also: #456, #789
Rebase vs. Merge
This section is a TL;DR of Atlassian's excellent tutorial, "Merging vs. Rebasing".

Rebase
TL;DR: Applies your branch commits, one by one, upon the base branch, generating a new tree.

Merge
TL;DR: Creates a new commit, called (appropriately) a merge commit, with the differences between the two branches.

Why do some people prefer to rebase over merge?
I particularly prefer to rebase over merge. The reasons include:
- It generates a "clean" history, without unnecessary merge commits
- What you see is what you get, i.e., in a code review all changes come from a specific and entitled commit, avoiding changes hidden in merge commits
- More merges are resolved by the committer, and every merge change is in a commit with a proper message
- It's unusual to dig in and review merge commits, so avoiding them ensures all changes have a commit where they belong
When to squash
"Squashing" is the process of taking a series of commits and condensing them into a single commit.
It's useful in several situations, e.g.:
- Reducing commits with little or no context (typo corrections, formatting, forgotten stuff)
- Joining separate changes that make more sense when applied together
- Rewriting work in progress commits
When to avoid rebase or squash?
Avoid rebase and squash in public commits or in shared branches where multiple people work on. Rebase and squash rewrite history and overwrite existing commits, doing it on commits that are on shared branches (i.e., commits pushed to a remote repository or that comes from others branches) can cause confusion and people may lose their changes (both locally and remotely) because of divergent trees and conflicts.
Useful git commands
rebase -i
Use it to squash commits, edit messages, rewrite/delete/reorder commits, etc.
pick 002a7cc Improve description and update document title
pick 897f66d Add contributing section
pick e9549cf Add a section of Available languages
pick ec003aa Add "What is a commit" section"
pick bbe5361 Add source referencing as a point of help wanted
pick b71115e Add a section explaining the importance of commit messages
pick 669bf2b Add "Good practices" section
pick d8340d7 Add capitalization of first letter practice
pick 925f42b Add a practice to encourage good descriptions
pick be05171 Add a section showing good uses of message body
pick d115bb8 Add generic messages and column limit sections
pick 1693840 Add a section about language consistency
pick 80c5f47 Add commit message template
pick 8827962 Fix triple "m" typo
pick 9b81c72 Add "Rebase vs Merge" section
# Rebase 9e6dc75..9b81c72 onto 9e6dc75 (15 commands)
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into the previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented out
fixup
Use it to clean up commits easily and without needing a more complex rebase. This article has very good examples of how and when to do it.
cherry-pick
It is very useful to apply that commit you made on the wrong branch, without the need to code it again.
Example:
$ git cherry-pick 790ab21
[master 094d820] Fix English grammar in Contributing
Date: Sun Feb 25 23:14:23 2018 -0300
1 file changed, 1 insertion(+), 1 deletion(-)
add/checkout/reset [--patch | -p]
Let's say we have the following diff:
diff --git a/README.md b/README.md
index 7b45277..6b1993c 100644
--- a/README.md
+++ b/README.md
@@ -186,10 +186,13 @@ bebebe Corrige nome de método na classe InventoryBackend
``
# Bad (mixes English and Portuguese)
ababab Usa o InventoryBackendPool para recuperar o backend de estoque
-efefef Add `use` method to Credit model
cdcdcd Agora vai
``
+### Template
+
+This is a template, [written originally by Tim Pope](http://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html), which appears in the [_Pro Git Book_](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project).
+
## Contributing
Any kind of help would be appreciated. Example of topics that you can help me with:
@@ -202,3 +205,4 @@ Any kind of help would be appreciated. Example of topics that you can help me wi
- [How to Write a Git Commit Message](https://chris.beams.io/posts/git-commit/)
- [Pro Git Book - Commit guidelines](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project#_commit_guidelines)
+- [A Note About Git Commit Messages](https://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html)
We can use git add -p to add only the patches we want to, without the need to change the code that is already written.
It's useful to split a big change into smaller commits or to reset/checkout specific changes.
Stage this hunk [y,n,q,a,d,/,j,J,g,s,e,?]? s
Split into 2 hunks.
hunk 1
@@ -186,7 +186,6 @@
``
# Bad (mixes English and Portuguese)
ababab Usa o InventoryBackendPool para recuperar o backend de estoque
-efefef Add `use` method to Credit model
cdcdcd Agora vai
``
Stage this hunk [y,n,q,a,d,/,j,J,g,e,?]?
hunk 2
@@ -190,6 +189,10 @@
``
cdcdcd Agora vai
``
+### Template
+
+This is a template, [written originally by Tim Pope](http://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html), which appears in the [_Pro Git Book_](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project).
+
## Contributing
Any kind of help would be appreciated. Example of topics that you can help me with:
Stage this hunk [y,n,q,a,d,/,K,j,J,g,e,?]?
hunk 3
@@ -202,3 +205,4 @@ Any kind of help would be appreciated. Example of topics that you can help me wi
- [How to Write a Git Commit Message](https://chris.beams.io/posts/git-commit/)
- [Pro Git Book - Commit guidelines](https://git-scm.com/book/en/v2/Distributed-Git-Contributing-to-a-Project#_commit_guidelines)
+- [A Note About Git Commit Messages](https://tbaggery.com/2008/04/19/a-note-about-git-commit-messages.html)
Other interesting stuff
- https://whatthecommit.com/
- https://gitmoji.carloscuesta.me/
Like it?
Contributing
Any kind of help would be appreciated. Example of topics that you can help me with:
- Grammar and spelling corrections
- Translation to other languages
- Improvement of source referencing
- Incorrect or incomplete information
Inspirations, sources and further reading
- How to Write a Git Commit Message
- Pro Git Book - Commit guidelines
- A Note About Git Commit Messages
- Merging vs. Rebasing
- Pro Git Book - Rewriting History
https://www.cloudbees.com/blog/understanding-dockers-cmd-and-entrypoint-instructions
Understanding Docker's CMD and ENTRYPOINT Instructions
Written by: Ben Cane June 21, 2017
When creating a Docker container, the goal is generally that anyone could simply execute docker run <containername> and launch the container. In today's article, we are going to explore two key Dockerfile instructions that enable us to do just that. Let's explore the differences between the CMD and ENTRYPOINT instructions.
On the surface, the CMD and ENTRYPOINT instructions look like they perform the same function. However, once you dig deeper, it's easy to see that these two instructions perform completely different tasks.
ApacheBench Dockerfile
To help serve as an example, we're going to create a Docker container that simply executes the ApacheBench utility.
In earlier articles, we discovered the simplicity and usefulness of the ApacheBench load testing tool. However, this type of command-line utility is not generally the type of application one would "Dockerize." The general usage of Docker is focused more on creating services rather than single execution tools like ApacheBench.
The main reason behind this is that typically Docker containers are not built to accept additional parameters when launching. This makes it tricky to use a command-line tool within a container.
Let's see this in action by creating a Docker container that can be used to execute ApacheBench against any site.
FROM ubuntu:latest
RUN apt-get update && \
apt-get install -y apache2-utils && \
rm -rf /var/lib/apt/lists/*
CMD ab
In the Dockerfile, we are simply using the ubuntu:latest image as our base container image, installing the apache2-utils package, and then defining that the command for this container is the ab command.
Since this Docker container is planned to be used as an executor for the ab command, it makes sense to set the CMD instruction value to the ab command. However, if we run this container we will start to see an interesting difference between this container and other application containers.
Before we can run this container, however, we first need to build it. We can do so with the docker build command.
$ docker build -t ab .
Sending build context to Docker daemon 2.048 kB
Step 1/3 : FROM ubuntu:latest
---> ebcd9d4fca80
Step 2/3 : RUN apt-get update && apt-get install -y apache2-utils && rm -rf /var/lib/apt/lists/*
---> Using cache
---> d9304ff09c98
Step 3/3 : CMD ab
---> Using cache
---> ecfc71e7fba9
Successfully built ecfc71e7fba9
When building this container, I tagged the container with the name of ab. This means we can simply launch this container via the name ab.
$ docker run ab
ab: wrong number of arguments
Usage: ab [options] [http[s]://]hostname[:port]/path
Options are:
-n requests Number of requests to perform
-c concurrency Number of multiple requests to make at a time
-t timelimit Seconds to max. to spend on benchmarking
This implies -n 50000
-s timeout Seconds to max. wait for each response
Default is 30 seconds
When we run the ab container, we get back an error from the ab command as well as usage details. The reason for this is that we defined the CMD instruction to the ab command without specifying any flags or target host to load test against. This CMDinstruction is used to define what command the container should execute when launched. Since we defined that as the abcommand without arguments, it executed the ab command without arguments.
However, like most command-line tools, that simply isn't how ab works. With ab, you need to specify what URL you wish to test against.
What we can do in order to make this work is override the CMD instruction when we launch the container. We can do this by adding the command and arguments we wish to execute at the end of the docker run command.
$ docker run ab ab http://bencane.com/
Benchmarking bencane.com (be patient).....done
Concurrency Level: 1
Time taken for tests: 0.343 seconds
Complete requests: 1
Failed requests: 0
Total transferred: 98505 bytes
HTML transferred: 98138 bytes
Requests per second: 2.92 [#/sec] (mean)
Time per request: 342.671 [ms] (mean)
Time per request: 342.671 [ms] (mean, across all concurrent requests)
Transfer rate: 280.72 [Kbytes/sec] received
When we add ab http://bencane.com to the end of our docker run command, we are able to override the CMD instruction and execute the ab command successfully. However, while we were successful, this process of overriding the CMD instruction is rather clunky.
ENTRYPOINT
This is where the ENTRYPOINT instruction shines. The ENTRYPOINT instruction works very similarly to CMD in that it is used to specify the command executed when the container is started. However, where it differs is that ENTRYPOINT doesn't allow you to override the command.
Instead, anything added to the end of the docker run command is appended to the command. To understand this better, let's go ahead and change our CMD instruction to the ENTRYPOINT instruction.
FROM ubuntu:latest
RUN apt-get update && \
apt-get install -y apache2-utils && \
rm -rf /var/lib/apt/lists/*
ENTRYPOINT ["ab"]
After editing the Dockerfile, we will need to build the image once again.
$ docker build -t ab .
Sending build context to Docker daemon 2.048 kB
Step 1/3 : FROM ubuntu:latest
---> ebcd9d4fca80
Step 2/3 : RUN apt-get update && apt-get install -y apache2-utils && rm -rf /var/lib/apt/lists/*
---> Using cache
---> d9304ff09c98
Step 3/3 : ENTRYPOINT ab
---> Using cache
---> aa020cfe0708
Successfully built aa020cfe0708
Now, we can run the ab container once again; however, this time, rather than specifying ab http://bencane.com, we can simply add http://bencane.com to the end of the docker run command.
$ docker run ab http://bencane.com/
Benchmarking bencane.com (be patient).....done
Concurrency Level: 1
Time taken for tests: 0.436 seconds
Complete requests: 1
Failed requests: 0
Total transferred: 98505 bytes
HTML transferred: 98138 bytes
Requests per second: 2.29 [#/sec] (mean)
Time per request: 436.250 [ms] (mean)
Time per request: 436.250 [ms] (mean, across all concurrent requests)
Transfer rate: 220.51 [Kbytes/sec] received
As the above example shows, we have now essentially turned our container into an executable. If we wanted, we could add additional flags to the ENTRYPOINT instruction to simplify a complex command-line tool into a single-argument Docker container.
Be careful with syntax
One imporant thing to call out about the ENTRYPOINT instruction is that syntax is critical. Technically, ENTRYPOINT supports both the ENTRYPOINT ["command"] syntax and the ENTRYPOINT command syntax. However, while both of these are supported, they have two different meanings and change how ENTRYPOINT works.
Let's change our Dockerfile to match this syntax and see how it changes our containers behavior.
FROM ubuntu:latest
RUN apt-get update && \
apt-get install -y apache2-utils && \
rm -rf /var/lib/apt/lists/*
ENTRYPOINT ab
With the changes made, let's build the container.
$ docker build -t ab .
Sending build context to Docker daemon 2.048 kB
Step 1/3 : FROM ubuntu:latest
---> ebcd9d4fca80
Step 2/3 : RUN apt-get update && apt-get install -y apache2-utils && rm -rf /var/lib/apt/lists/*
---> Using cache
---> d9304ff09c98
Step 3/3 : ENTRYPOINT ab
---> Using cache
---> bbfe2686a064
Successfully built bbfe2686a064
With the container built, let's run it again using the same options as before.
$ docker run ab http://bencane.com/
ab: wrong number of arguments
Usage: ab [options] [http[s]://]hostname[:port]/path
Options are:
-n requests Number of requests to perform
-c concurrency Number of multiple requests to make at a time
-t timelimit Seconds to max. to spend on benchmarking
This implies -n 50000
-s timeout Seconds to max. wait for each response
Default is 30 seconds
It looks like we are back to the same behavior as the CMD instruction. However, if we try to override the ENTRYPOINT we will see different behavior than when we overrode the CMD instruction.
$ docker run ab ab http://bencane.com/
ab: wrong number of arguments
Usage: ab [options] [http[s]://]hostname[:port]/path
Options are:
-n requests Number of requests to perform
-c concurrency Number of multiple requests to make at a time
-t timelimit Seconds to max. to spend on benchmarking
This implies -n 50000
-s timeout Seconds to max. wait for each response
Default is 30 seconds
With the ENTRYPOINT instruction, it is not possible to override the instruction during the docker run command execution like we are with CMD. This highlights another usage of ENTRYPOINT, as a method of ensuring that a specific command is executed when the container in question is started regardless of attempts to override the ENTRYPOINT.
Summary
In this article, we covered quite a bit about CMD and ENTRYPOINT; however, there are still additional uses of these two instructions that allow you to customize how a Docker container starts. To see some of these examples, you can take a look at Docker's Dockerfilereference docs.
With the above example however, we now have a way to "Dockerize" simple command-line tools such as ab, which opens up quite a few interesting use cases. If you have one, feel free to share it in the comments below.
https://scattered-thoughts.net/writing/against-sql
Against SQL
Jamie Brandon, Last updated 2021-07-09
TLDR
The relational model is great:
- A shared universal data model allows cooperation between programs written in many different languages, running on different machines and with different lifespans.
- Normalization allows updating data without worrying about forgetting to update derived data.
- Physical data independence allows changing data-structures and query plans without having to change all of your queries.
- Declarative constraints clearly communicate application invariants and are automatically enforced.
- Unlike imperative languages, relational query languages don't have false data dependencies created by loop counters and aliasable pointers. This makes relational languages:
- A good match for modern machines. Data can be rearranged for more compact layouts, even automatic compression. Operations can be reordered for high cache locality, pipeline-friendly hot loops, simd etc.
- Amenable to automatic parallelization.
- Amenable to incremental maintenance.
But SQL is the only widely-used implementation of the relational model, and it is:
This isn't just a matter of some constant programmer overhead, like SQL queries taking 20% longer to write. The fact that these issues exist in our dominant model for accessing data has dramatic downstream effects for the entire industry:
- Complexity is a massive drag on quality and innovation in runtime and tooling
- The need for an application layer with hand-written coordination between database and client renders useless most of the best features of relational databases
The core message that I want people to take away is that there is potentially a huge amount of value to be unlocked by replacing SQL, and more generally in rethinking where and how we draw the lines between databases, query languages and programming languages.
Inexpressive
Talking about expressiveness is usually difficult, since it's a very subjective measure. But SQL is a particularly inexpressive language. Many simple types and computations can't be expressed at all. Others require far more typing than they need to. And often the structure is fragile - small changes to the computation can require large changes to the code.
Can't be expressed
Let's start with the easiest examples - things that can't be expressed in SQL at all.
For example, SQL:2016 added support for json values. In most languages json support is provided by a library. Why did SQL have to add it to the language spec?
First, while SQL allows user-defined types, it doesn't have any concept of a sum type. So there is no way for a user to define the type of an arbitrary json value:
#![allow(unused)] fn main() { enum Json { Null, Bool(bool), Number(Number), String(String), Array(Vec<Value>), Object(Map<String, Value>), } }
The usual response to complaints about the lack of sum types in sql is that you should use an id column that joins against multiple tables, one for each possible type.
create table json_value(id integer);
create table json_bool(id integer, value bool)
create table json_number(id integer, value double);
create table json_string(id integer, value text);
create table json_array(id integer);
create table json_array_elements(id integer, position integer, value json_value, foreign key (value) references json_value(id));
create table json_object(id integer);
create table json_object_properties(id integer, key text, value json_value, foreign key (value) references json_value(id));
This works for data modelling (although it's still clunky because you must try joins against each of the tables at every use site rather than just ask the value which table it refers to). But this solution is clearly inappropriate for modelling a value like json that can be created inside scalar expressions, where inserts into some global table are not allowed.
Second, parsing json requires iteration. SQLs with recursive is limited to linear recursion and has a bizarre choice of semantics - each step can access only the results from the previous step, but the result of the whole thing is the union of all the steps. This makes parsing, and especially backtracking, difficult. Most SQL databases also have a procedural sublanguage that has explicit iteration, but there are few commonalities between the languages in different databases. So there is no pure-SQL json parser that works across different databases.
Third, most databases have some kind of extension system that allows adding new types and functions using a regular programming language (usually c). Indeed, this is how json support first appeared in many databases. But again these extension systems are not at all standardized so it's not feasible to write a library that works across many databases.
So instead the best we can do is add json to the SQL spec and hope that all the databases implement it in a compatible way (they don't).
The same goes for xml, regular expressions, windows, multi-dimensional arrays, periods etc.
Compare how flink exposes windowing:
- The interface is made out of objects and function calls, both of which are first-class values and can be stored in variables and passed as function arguments.
- The style of windowing is defined by a WindowAssigner which simply takes a row and returns a set of window ids.
- Several common styles of windows are provided as library code.
Vs SQL:
- The interface adds a substantial amount of new syntax to the language.
- The windowing style is purely syntactic - it is not a value that can be assigned to a variable or passed to a function. This means that we can't compress common windowing patterns.
- Only a few styles of windowing are provided and they are hard-coded into the language.
Why is the SQL interface defined this way?
Much of this is simply cultural - this is just how new SQL features are designed.
But even if we wanted to mimic the flink interface we couldn't do it in SQL.
- Functions are not values that can be passed around, and they can't take tables or other functions as arguments. So complex operations such as windowing can't be added as stdlib functions.
- Without sum types we can't even express the hardcoded windowing styles as a value. So we're forced to add new syntax whenever we want to parameterize some operation with several options.
Verbose to express
Joins are at the heart of the relational model. SQL's syntax is not unreasonable in the most general case, but there are many repeated join patterns that deserve more concise expression.
By far the most common case for joins is following foreign keys. SQL has no special syntax for this:
select foo.id, quux.value
from foo, bar, quux
where foo.bar_id = bar.id and bar.quux_id = quux.id
Compare to eg alloy, which has a dedicated syntax for this case:
foo.bar.quux
Or libraries like pandas or flink, where it's trivial to write a function that encapsulates this logic:
fk_join(foo, 'bar_id', bar, 'quux_id', quux)
Can we write such a function in sql? Most databases don't allow functions to take tables as arguments, and also require the column names and types of the input and output tables to be fixed when the function is defined. SQL:2016 introduced polymorphic table functions, which might allow writing something like fk_join but so far only oracle has implemented them (and they didn't follow the spec!).
Verbose syntax for such core operations has chilling effects downstream, such as developers avoiding 6NF even in situations where it's useful, because all their queries would balloon in size.
Fragile structure
There are many cases where a small change to a computation requires totally changing the structure of the query, but subqueries are my favourite because they're the most obvious way to express many queries and yet also provide so many cliffs to fall off.
-- for each manager, find their employee with the highest salary
> select
> manager.name,
> (select employee.name
> from employee
> where employee.manager = manager.name
> order by employee.salary desc
> limit 1)
> from manager;
name | name
-------+------
alice | bob
(1 row)
-- what if we want to return the salary too?
> select
> manager.name,
> (select employee.name, employee.salary
> from employee
> where employee.manager = manager.name
> order by employee.salary desc
> limit 1)
> from manager;
ERROR: subquery must return only one column
LINE 3: (select employee.name, employee.salary
^
-- the only solution is to change half of the lines in the query
> select manager.name, employee.name, employee.salary
> from manager
> join lateral (
> select employee.name, employee.salary
> from employee
> where employee.manager = manager.name
> order by employee.salary desc
> limit 1
> ) as employee
> on true;
name | name | salary
-------+------+--------
alice | bob | 100
(1 row)
This isn't terrible in such a simple example, but in analytics it's not uncommon to have to write queries that are hundreds of lines long and have many levels of nesting, at which point this kind of restructuring is laborious and error-prone.
Incompressible
Code can be compressed by extracting similar structures from two or more sections. For example, if a calculation was used in several places we could assign it to a variable and then use the variable in those places. Or if the calculation depended on different inputs in each place, we could create a function and pass the different inputs as arguments.
This is programming 101 - variables, functions and expression substitution. How does SQL fare on this front?
Variables
Scalar values can be assigned to variables, but only as a column inside a relation. You can't name a thing without including it in the result! Which means that if you want a temporary scalar variable you must introduce a new select to get rid off it. And also name all your other values.
-- repeated structure
select a+((z*2)-1), b+((z*2)-1) from foo;
-- compressed?
select a2, b2 from (select a+tmp as a2, b+tmp as b2, (z*2)-1 as tmp from foo);
You can use as to name scalar values anywhere they appear. Except in a group by.
-- can't name this value
> select x2 from foo group by x+1 as x2;
ERROR: syntax error at or near "as"
LINE 1: select x2 from foo group by x+1 as x2;
-- sprinkle some more select on it
> select x2 from (select x+1 as x2 from foo) group by x2;
?column?
----------
(0 rows)
Rather than fix this bizarre oversight, the SQL spec allows a novel form of variable naming - you can refer to a column by using an expression which produces the same parse tree as the one that produced the column.
-- this magically works, even though x is not in scope in the select
> select (x + 1)*2 from foo group by x+1;
?column?
----------
(0 rows)
-- but this doesn't, because it isn't the same parse tree
> select (x + +1)*2 from foo group by x+1;
ERROR: column "foo.x" must appear in the GROUP BY clause or be used in an aggregate function
LINE 1: select (x + +1)*2 from foo group by x+1;
^
Of course, you can't use this feature across any kind of syntactic boundary. If you wanted to, say, assign this table to a variable or pass it to a function, then you need to both repeat the expression and explicitly name it;
> with foo_plus as (select x+1 from foo group by x+1)
> select (x+1)*2 from foo_plus;
ERROR: column "x" does not exist
LINE 2: select (x+1)*2 from foo_plus;
^
> with foo_plus as (select x+1 as x_plus from foo group by x+1)
> select x_plus*2 from foo_plus;
?column?
----------
(0 rows)
SQL was first used in the early 70s, but if your repeated value was a table then you were out of luck until CTEs were added in SQL:99.
-- repeated structure
select *
from
(select x, x+1 as x2 from foo) as foo1
left join
(select x, x+1 as x2 from foo) as foo2
on
foo1.x2 = foo2.x;
-- compressed?
with foo_plus as
(select x, x+1 as x2 from foo)
select *
from
foo_plus as foo1
left join
foo_plus as foo2
on
foo1.x2 = foo2.x;
Functions
Similarly, if your repeated calculations have different inputs then you were out of luck until scalar functions were added in SQL:99.
-- repeated structure
select a+((x*2)-1), b+((y*2)-1) from foo;
-- compressed?
create function bar(integer, integer) returns integer
as 'select $1+(($2*2)-1);'
language sql;
select bar(a,x), bar(b,y) from foo;
Functions that return tables weren't added until SQL:2003.
-- repeated structure
(select x from foo)
union
(select x+1 from foo)
union
(select x+2 from foo)
union
(select x from bar)
union
(select x+1 from bar)
union
(select x+2 from bar);
-- compressed?
create function increments(integer) returns setof integer
as $$
(select $1)
union
(select $1+1)
union
(select $1+2);
$$
language sql;
(select increments(x) from foo)
union
(select increments(x) from bar);
What if you want to compress a repeated calculation that produces more than one table as a result? Tough!
What if you want to compress a repeated calculation where one of the inputs is a table? The spec doesn't explicitly disallow this, but it isn't widely supported. SQL server can do it with this lovely syntax:
-- compressed?
create type foo_like as table (x int);
create function increments(@foo foo_like readonly) returns table
as return
(select x from @foo)
union
(select x+1 from @foo)
union
(select x+2 from @foo);
declare @foo as foo_like;
insert into @foo select * from foo;
declare @bar as foo_like;
insert into @bar select * from bar;
increments(@foo) union increments(@bar);
Aside from the weird insistence that we can't just pass a table directly to our function, this example points to a more general problem: column names are part of types. If in our example bar happened to have a different column name then we would have had to write:
increments(@foo) union increments(select y as x from @bar)
Since columns names aren't themselves first-class this makes it hard to compress repeated structure that happens to involve different names:
-- repeated structure
select a,b,c,x,y,z from foo order by a,b,c,x,y,z;
-- fantasy land
with ps as (columns 'a,b,c,x,y,z')
select $ps from foo order by $ps
The same is true of windows, collations, string encodings, the part argument to extract ... pretty much anything that involves one of the several hundred SQL keywords.
Functions and types are also not first-class, so repeated structures involving different functions or types can't be compressed.
Expression substitution
To be able to compress repeated structure we must be able to replace the verbose version with the compressed version. In many languages, there is a principle that it's always possible to replace any expression with another expression that has the same value. SQL breaks this principle in (at least) two ways.
Firstly, it's only possible to substitute one expression for another when they are both the same type of expression. SQL has statements (DDL), table expressions and scalar expressions.
Using a scalar expression inside a table expression requires first wrapping the entire thing with a new select.
Using a table expression inside a scalar expression is generally not possible, unless the table expression returns only 1 column and either a) the table expression is guaranteed to return at most 1 row or b) your usage fits into one of the hard-coded patterns such as exists. Otherwise, as we saw in the most-highly-paid-employee example earlier, it must be rewritten as a lateral join against the nearest enclosing table expression.
Secondly, table expressions aren't all made equal. Some table expressions depend not only on the value of an inner expression, but the syntax. For example:
-- this is fine - the spec allows `order by` to see inside the `(select ...)`
-- and make use of a column `y` that doesn't exist in the returned value
> (select x from foo) order by y;
x
---
3
(1 row)
-- same value in the inner expression
-- but the spec doesn't have a syntactic exception for this case
> (select x from (select x from foo) as foo2) order by y;
ERROR: column "y" does not exist
LINE 1: (select x from (select x from foo) as foo2) order by y;
In such cases it's not possible to compress repeated structure without first rewriting the query to explicitly select and then drop the magic column:
select x from ((select x,y from foo) order by y);
Non-porous
I took the term 'porous' from Some Were Meant For C, where Stephen Kell argues that the endurance of c is down to it's extreme openness to interaction with other systems via foreign memory, FFI, dynamic linking etc. He contrasts this with managed languages which don't allow touching anything in the entire memory space without first notifying the GC, have their own internal notions of namespaces and linking which they don't expose to the outside world, have closed build systems which are hard to interface with other languages' build systems etc.
For non-porous languages to succeed they have to eat the whole world - gaining enough users that the entire programming ecosystem can be duplicated within their walled garden. But porous languages can easily interact with existing systems and make use of existing libraries and tools.
Whether or not you like this argument as applied to c, the notion of porousness itself is a useful lens for system design. When we apply it to SQL databases, we see while individual databases are often porous in many aspects of their design, the mechanisms are almost always not portable. So while individual databases can be extended in many ways, the extensions can't be shared between databases easily and the SQL spec is still left trying to eat the whole world.
Language level
Most SQL databases have language-level escape hatches for defining new types and functions via a mature programming language (usually c). The syntax for declaring these in SQL is defined in the spec but the c interface and calling convention is not, so these are not portable across different databases.
-- sql side
CREATE FUNCTION add_one(integer) RETURNS integer
AS 'DIRECTORY/funcs', 'add_one'
LANGUAGE C STRICT;
// c side
#include "postgres.h"
#include <string.h>
#include "fmgr.h"
#include "utils/geo_decls.h"
PG_MODULE_MAGIC;
PG_FUNCTION_INFO_V1(add_one);
Datum
add_one(PG_FUNCTION_ARGS)
{
int32 arg = PG_GETARG_INT32(0);
PG_RETURN_INT32(arg + 1);
}
Runtime level
Many SQL databases also have runtime-level extension mechanisms for creating new index types and storage methods (eg postgis) and also for supplying hints to the optimizer. Again, these extensions are not portable across different implementations. At this level it's hard to see how they could be, as they can be deeply entangled with design decisions in the database runtime, but it's worth noting that if they were portable then much of the SQL spec would not need to exist.
The SQL spec also has an extension SQL/MED which defines how to query data that isn't owned by the database, but it isn't widely or portably implemented.
Interface level
At the interface level, the status quo is much worse. Each database has a completely different interface protocol.
The protocols I'm familiar with are all ordered, synchronous and allow returning only one relation at a time. Many don't even support pipelining. For a long time SQL also lacked any way to return nested structures and even now (with json support) it's incredibly verbose.
This meant that if you wanted to return, say, a list of user profiles and their followers, you would have to make multiple round-trips to the database. Latency considerations make this unfeasible over longer distances. This practically mandates the existence of an application layer whose main purpose is to coalesce multiple database queries and reassemble their nested structure using hand-written joins over the output relations - duplicating work that the database is supposed to be good at.
Protocols also typically return metadata as text in an unspecified format with no parser supplied (even if there is a binary protocol for SQL values, metadata is still typically returned as a 1-row 1-column table containing a string). This makes it harder than necessary to build any kind of tooling outside of the database. Eg if we wanted to parse plans and verify that they don't contain any table scans or nested loops.
Similarly, SQL is submitted to the database as a text format identical to what the programmer would type. Since the syntax is so complicated, it's difficult for other languages to embed, validate and escape SQL queries and to figure out what types they return. (Query parameters are not a panacea for escaping - often you need to vary query structure depending on user input, not just values).
SQL databases are also typically monolithic. You can't, for example, just send a query plan directly to postgres. Or call the planner as a library to help make operational forecasts based on projected future workloads. Looking at the value unlocked by eg pg_query gives the sense that there could be a lot to gain by exposing more of the innards of SQL systems.
Complexity drag
In modern programming languages, the language itself consists of a small number of carefully chosen primitives. Programmers combine these to build up the rest of the functionality, which can be shared in the form of libraries. This lowers the burden on the language designers to foresee every possible need and allows new implementations to reuse existing functionality. Eg if you implement a new javascript interpreter, you get the whole javascript ecosystem for free.
Because SQL is so inexpressive, incompressible and non-porous it was never able to develop a library ecosystem. Instead, any new functionality that is regularly needed is added to the spec, often with it's own custom syntax. So if you develop a new SQL implementation you must also implement the entire ecosystem from scratch too because users can't implement it themselves.
This results in an enormous language.
The core SQL language is defined in part 2 (of 9) of the SQL 2016 spec. Part 2 alone is 1732 pages. By way of comparison, the javascript 2021 spec is 879 pages and the c++ 2020 spec is 1853 pages.
But the SQL spec is not even complete!
A quick grep of the SQL standard indicates 411 occurrences of implementation-defined behavior. And not in some obscure corner cases, this includes basic language features. For a programming language that would be ridiculous. But for some reason people accept the fact that SQL is incredibly under-specified, and that it is impossible to write even relatively simple analytical queries in a way that is portable across database systems.
Notably, the spec does not define type inference at all, which means that the results of basic arithmetic are implementation-defined. Here is an example from the sqlite test suite in various databases:
sqlite> SELECT DISTINCT - + 34 + + - 26 + - 34 + - 34 + + COALESCE ( 93, COUNT ( * ) + + 44 - 16, - AVG ( + 86 ) + 12 ) / 86 * + 55 * + 46;
2402
postgres> SELECT DISTINCT - + 34 + + - 26 + - 34 + - 34 + + COALESCE ( 93, COUNT ( * ) + + 44 - 16, - AVG ( + 86 ) + 12 ) / 86 * + 55 * + 46;
?column?
-----------------------
2607.9302325581395290
(1 row)
mariadb> SELECT DISTINCT - + 34 + + - 26 + - 34 + - 34 + + COALESCE ( 93, COUNT ( * ) + + 44 - 16, - AVG ( + 86 ) + 12 ) / 86 * + 55 * + 46;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near '* ) + + 44 - 16, - AVG ( + 86 ) + 12 ) / 86 * + 55 * + 46' at line 1
The spec also declares that certain operations should produce errors when evaluated, but since it doesn't define an evaluation order the decision is left down to the optimizer. A query that runs fine in your database today might return an error tomorrow on the same data if the optimizer produces a different plan.
sqlite> select count(foo.bar/0) from (select 1 as bar) as foo where foo.bar = 0;
0
postgres> select count(foo.bar/0) from (select 1 as bar) as foo where foo.bar = 0;
ERROR: division by zero
mariadb> select count(foo.bar/0) from (select 1 as bar) as foo where foo.bar = 0;
+------------------+
| count(foo.bar/0) |
+------------------+
| 0 |
+------------------+
1 row in set (0.001 sec)
And despite being enormous and not even definining the whole language, the spec still manages to define a language so anemic that every database ends up with a raft of non-standard extensions to compensate.
Even if all the flaws I listed in the previous sections were to be fixed in the future, SQL already ate a monstrous amount of complexity in workarounds for those flaws and that complexity will never be removed from the spec. This complexity has a huge impact on the effort required to implement a new SQL engine.
To take an example close to my heart: Differential dataflow is a dataflow engine that includes support for automatic parallel execution, horizontal scaling and incrementally maintained views. It totals ~16kloc and was mostly written by a single person. Materialize adds support for SQL and various data sources. To date, that has taken ~128kloc (not including dependencies) and I estimate ~15-20 engineer-years. Just converting SQL to the logical plan takes ~27kloc, more than than the entirety of differential dataflow.
Similarly, sqlite looks to have ~212kloc and duckdb ~141kloc. The count for duckdb doesn't even include the parser that they (sensibly) borrowed from postgres, which at ~47kloc is much larger than the entire ~30kloc codebase for lua.
Materialize passes more than 7 million tests, including the entire sqlite logic test suite and much of the cockroachdb logic test suite. And yet they are still discovering (my) bugs in such core components as name resolution, which in any sane language would be trivial.
The entire database industry is hauling a massive SQL-shaped parachute behind them. This complexity creates a drag on everything downstream.
Quality of implementation suffers
There is so much ground to cover that it's not possible to do a good job of all of it. Subqueries, for example, add some much-needed expressiveness to SQL but their use is usually not recommended because most databases optimize them poorly or not at all.
This affects UX too. Every SQL database I've used has terrible syntax errors.
sqlite> with q17_part as (
...> select p_partkey from part where
...> p_brand = 'Brand#23'
...> and p_container = 'MED BOX'
...> ),
...> q17_avg as (
...> select l_partkey as t_partkey, 0.2 * avg(l_quantity) as t_avg_quantity
...> from lineitem
...> where l_partkey IN (select p_partkey from q17_part)
...> group by l_partkey
...> ),
...> q17_price as (
...> select
...> l_quantity,
...> l_partkey,
...> l_extendedprice
...> from
...> lineitem
...> where
...> l_partkey IN (select p_partkeyfrom q17_part)
...> ),
...> select cast(sum(l_extendedprice) / 7.0 as decimal(32,2)) as avg_yearly
...> from q17_avg, q17_price
...> where
...> t_partkey = l_partkey and l_quantity < t_avg_quantity;
Error: near "select": syntax error
But it's hard to produce good errors when your grammar contains 1732 non-terminals. And several hundred keywords. And allows using (some) keywords as identifiers. And contains many many ambiguities which mean that typos are often valid but nonsensical SQL.
Innovatation at the implementation level is gated
Incremental maintenance, parallel execution, provenance, equivalence checking, query synthesis etc. These show up in academic papers, produce demos for simplified subsets of SQL, and then disappear.
In the programming language world we have a smooth pipeline that takes basic research and applies it to increasingly realistic languages, eventually producing widely-used industrial-quality tools. But in the database world there is a missing step between demos on toy relational algebras and handling the enormity of SQL, down which most compelling research quietly plummets. Bringing anything novel to a usable level requires a substantial investment of time and money that most researchers simply don't have.
Portability is a myth
The spec is too large and too incomplete, and the incentives to follow the spec too weak. For example, the latest postgres docs note that "at the time of writing, no current version of any database management system claims full conformance to Core SQL:2016". It also lists a few dozen departures from the spec.
This is exacerbated by the fact that every database also has to invent myriad non-standard extensions to cover the weaknesses of standard SQL.
Where the average javascript program can be expected to work in any interpreter, and the average c program might need to macro-fy some compiler builtins, the average body of SQL queries will need serious editing to run on a different database and even then can't be expected to produce the same answers.
One of the big selling points for supporting SQL in a new database is that existing tools that emit SQL will be able to run unmodified. But in practice, such tools almost always end up maintaining separate backends for every dialect, so unless you match an existing database bug-for-bug you'll still have to add a new backend to every tool.
Similarly, users will be able to carry across some SQL knowledge, but will be regularly surprised by inconsistencies in syntax, semantics and the set of available types and functions. And unlike the programming language world they won't be able to carry across any existing code or libraries.
This means that the network effects of SQL are much weaker than they are for programming languages, which makes it all the more surprising that we have a bounty of programming languages but only one relational database language.
The application layer
The original idea of relational databases was that they would be queried directly from the client. With the rise of the web this idea died - SQL is too complex to be easily secured against adversarial input, cache invalidation for SQL queries is too hard, and there is no way to easily spawn background tasks (eg resizing images) or to communicate with the rest of the world (eg sending email). And the SQL language itself was not an appealing target for adding these capabilities.
So instead we added the 'application layer' - a process written in a reasonable programming language that would live between the database and the client and manage their communication. And we invented ORM to patch over the weaknesses of SQL, especially the lack of compressibility.
This move was necessary, but costly.
ORMs are prone to n+1 query bugs and feral concurrency. To rephrase, they are bad at efficiently querying data and bad at making use of transactions - two of the core features of relational databases.
As for the application layer: Converting queries into rest endpoints by hand is a lot of error-prone boilerplate work. Managing cache invalidation by hand leads to a steady supply of bugs. If endpoints are too fine-grained then clients have to make multiple roundtrip calls, but if they're too coarse then clients waste bandwidth on data they didn't need. And there is no hope of automatically notifying clients when the result of their query has changed.
The success of GraphQL shows that these pains are real and that people really do want to issue rich queries directly from the client. Compared to SQL, GraphQL is substantially easier to implement, easier to cache, has a much smaller attack surface, has various mechanisms for compressing common patterns, makes it easy to follow foreign keys and return nested results, has first-class mechanisms for interacting with foreign code and with the outside world, has a rich type system (with union types!), and is easy to embed in other languages.
Similarly for firebase (before it was acqui-smothered by google). It dropped the entire application layer and offered streaming updates to client-side queries, built-in access control, client-side caching etc. Despite offering very little in the way of runtime innovation compared to existing databases, it was able to succesfully compete by recognizing that the current division of database + sql + orm + application-layer is a historical accident and can be dramatically simplified.
The overall vibe of the NoSQL years was "relations bad, objects good". I fear that what many researchers and developers are taking away from the success of GraphQL and co is but a minor update - "relations bad, ~objects~ graphs good".
This is a mistake. GraphQL is still more or less a relational model, as evidenced by the fact that it's typically backed by wrappers like hasura that allow taking advantage of the mature runtimes of relational databases. The key to the success of GraphQL was not doing away with relations, but recognizing and fixing the real flaws in SQL that were hobbling relational databases, as well as unbundling the query language from a single monolithic storage and execution engine.
After SQL?
To summarize:
- Design flaws in the SQL language resulted in a language with no library ecosystem and a burdensome spec which limits innovation.
- Additional design flaws in SQL database interfaces resulted in moving as much logic as possible to the application layer and limiting the use of the most valuable features of the database.
- It's probably too late to fix either of these.
But the idea of modelling data with a declarative disorderly language is still valuable. Maybe more so than ever, given the trends in hardware. What should a new language learn from SQL's successes and mistakes?
We can get pretty far by just negating every mistake listed in this post, while ensuring we retain the ability to produce and optimize query plans:
- Start with the structure that all modern languages have converged towards.
- Everything is an expression.
- Variables and functions have compact syntax.
- Few keywords - most things are stdlib functions rather than builtin syntax.
- Have an explicit type system rather than totally disjoint syntax for scalar expressions vs table expressions.
- Ensure that it's always possible to replace a given expression with another expression that has the same type and value.
- Define a (non-implementation specific) system for distributing and loading (and unloading!) libraries.
- Keep the spec simple and complete.
- Simple denotational semantics for the core language.
- Completely specify type inference, error semantics etc.
- Should be possible for an experienced engineer to throw together a slow but correct interpreter in a week or two.
- Encode semantics in a model checker or theorem prover to eg test optimizations. Ship this with the spec.
- Lean on wasm as an extension language - avoids having to spec arithemetic, strings etc if they can be defined as a library over some bits type.
- Make it compressible.
- Allow functions to take relations and other functions are arguments (can be erased by specialization before planning, ala rust or julia).
- Allow functions to operate on relations polymorphically (ie without having to fix the columns and types when writing the function).
- Make column names, orderings, collations, window specifications etc first-class values rather than just syntax (can use staging ala zig's comptime if these need to be constant at planning time).
- Compact syntax for simple joins (eg snowflake schemas, graph traversal).
- True recursion / fixpoints (allows expressing iterative algorithms like parsing).
- Make it porous.
- Allow defining new types, functions, indexes, plan operators etc via wasm plugins (with the calling convention etc in the spec).
- Expose plans, hints etc via api (not via strings).
- Spec both a human-friendly encoding and a tooling-friendly encoding (probably text vs binary like wasm). Ship an embedabble library that does parsing and type inference.
- Make returning nested structures (eg json) ergonomic, or at least allow returning multiple relations.
- Create a subset of the language that can be easily verified to run in reasonable time (eg no table scans, no nested loops).
- Allow exposing subset to clients via graphql-like authorization rules.
- Better layering.
- Separate as much as possible out into embeddable libraries (ala pg_query).
- Expose storage, transaction, execution as apis. The database server just receives and executes wasm against these apis.
- Distribute query parser/planner/compiler as a library so clients can choose to use modified versions to produce wasm for the server.
- Strategies for actually getting people to use the thing are much harder.
Tackling the entire stack at once seems challenging. Rethinkdb died. Datomic is alive but the company was acquihired. Neo4j, on the other hand, seems to be catnip for investors, so who knows.
A safer approach is to first piggy-back on existing databases runtime. EdgeDB uses the postgres runtime. Logica compiles to SQL. GraphQL has compilers for many different query languages.
Another option is to find an untapped niche and work outward from there. I haven't seen this done yet, but there are a lot of relational-ish query niches. Pandas targets data cleaning/analysis. Datascript is a front-end database. Bloom targets distributed systems algorithms. Semmle targets code analysis. Other potential niches include embedded databases in applications (ala fossils use of sqlite), incremental functions from state to UI, querying as an interface to the state of complex programs etc.
In a niche with less competition you could first grow the language and then try to expand the runtime outwards to cover more potential usecases, similar to how sqlite started as a tcl extension and ended up becoming the defacto standard for application-embedded databases, a common choice for data publishing format, and a backend for a variety of data-processing tools.
Questions? Comments? Just want to chat? jamie@scattered-thoughts.net
My work is currently funded by sharing thoughts and work in progress with people who sponsor me on github.
https://blog.healthchecks.io/2018/10/investigating-gmails-this-message-seems-dangerous/
Investigating Gmail’s “This message seems dangerous”
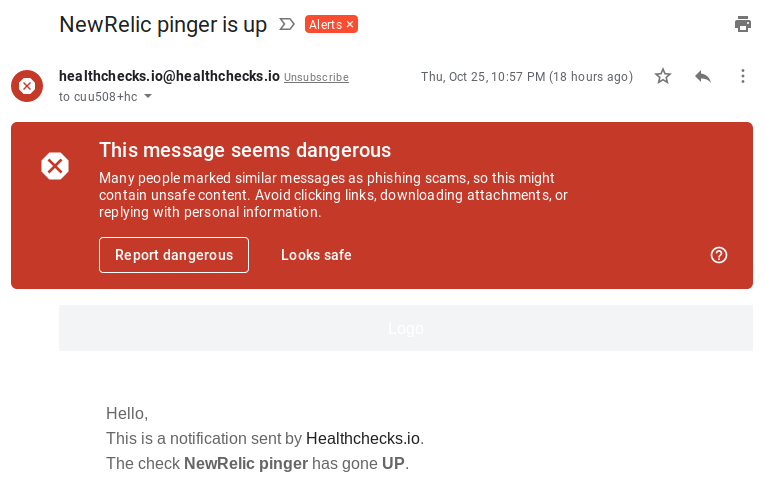
By Pēteris Caune / October 26, 2018
I’ve been receiving multiple user reports that Gmail shows a red “This message seems dangerous” banner above some of the emails sent by Healthchecks.io. I’ve even seen some myself:
The banner goes away after pressing “Looks safe”. And then, some time and some emails later, it is back.
It’s hard to know what exactly is causing the “This message seems dangerous” banner. Google of course won’t disclose the exact conditions for triggering it. The best I can do is try every fix I can think of.
Here’s what I’ve done so far.
SPF and DMARC records
For sending emails, Healthchecks.io uses Amazon SES. It’s super easy to set up DKIM records with AWS SES so that was already done from the beginning.
I’ve now also:
- Configured a custom MAIL FROM domain (“mail.healthchecks.io”)
- Added SPF and DMARC DNS records, and tested them with multiple online tools
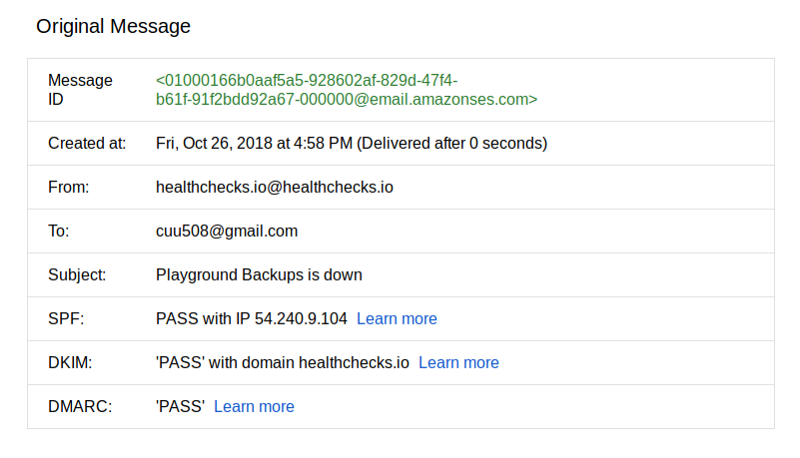
Update 20 November 2018: In DMARC reports, I’m noticing that a significant number of emails are failing both SPF and DKIM:

Apparently, last week, Google has processed more than 6000 emails that fail both SPF and DKIM checks. I’m thinking of two possibilities:
- an email forwarder is changing email contents (adding a tracking pixel, adding a “Scanned by Antivirus XYZ” note or similar). With email contents changed, DKIM signatures are no longer valid.
- somebody is spoofing emails from healthchecks.io addresses
Either way, I want to see if these messages are the culprit, so I’m changing the DMARC policy from “none” to “reject”. This instructs GMail to ignore and throw away email messages that fail both SPF and DKIM checks. Let’s see what happens!
List-Unsubscribe Header
Healthchecks.io notifications and monthly reports have always had an “Unsubscribe” link in the footer. I’ve now also added a “List-Unsubscribe” message header. Gmail seems to know how to use it:
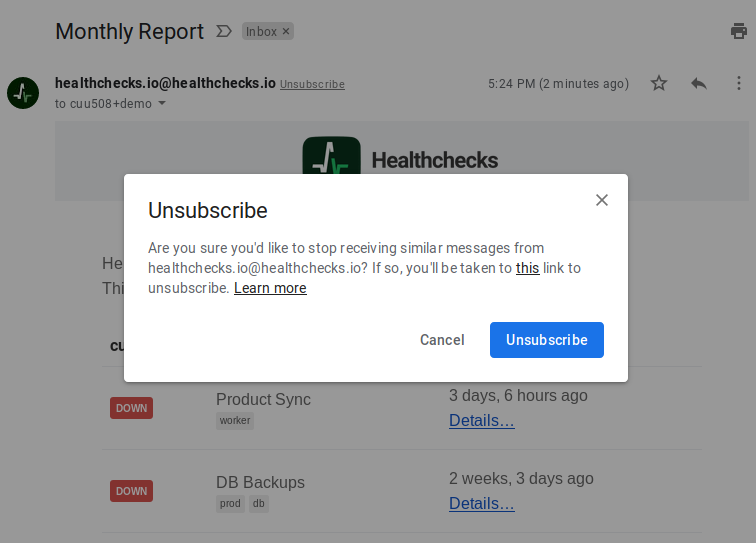
Maybe Gmail also looks for it as a spam/not-spam signal. As I said — I’m trying everything.
More Careful Handling of Monthly Reports
I’ looking into reducing the bounce and complaint rates of the monthly reports. The rates as currently reported by AWS SES:
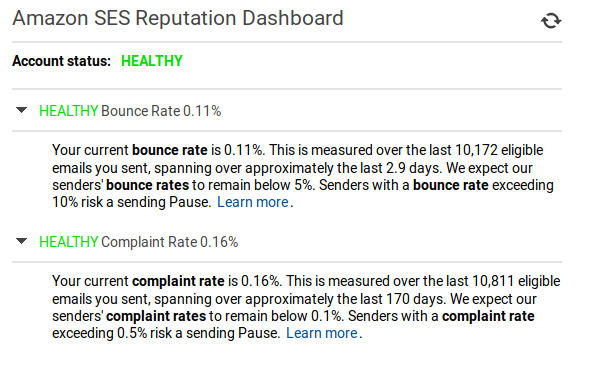
They don’t look too bad, but I’m trying to lower them some more with these two changes:
- When a monthly report bounces or receives a complaint, automatically and mercilessly disable monthly reports for that address. This was already being done for “XYZ is down” email notifications.
- If none of user’s checks have received any pings in the last 6 months, then that’s an inactive account: don’t send monthly reports for that user.
Reduce the Number of Links in Emails
Each Healthchecks.io alert email contains a summary of all of the checks in user’s account. For each check, it shows its current status, the date of last received ping, and a link to the check’s “Details” page on the website.
I removed the “Details…” links to see if Gmail is not liking emails with too many links.
7 December 2018: Solved?
I am cautiously optimistic that I’ve solved the issue by tweaking the contents of the emails. I haven’t seen the red Gmail warnings for a while now.
Here’s what happened: I noticed that removing the main content area from the email template makes Gmail’s red banner disappear. So I experimented with removing smaller and smaller chunks from the template until I had narrowed it down to a single CSS declaration:
/* MOBILE STYLES */
@media screen and (max-width: 525px) {
.mobile-hide {
display: none !important;
}
}
This class was used to hide some elements to make things fit on mobile screens. Remove usages of this class: no red banner. Add it back: red banner is back! I tested this a number of times to make sure it was not just a coincidence.
Conclusion
If you are seeing “This message seems dangerous” banner above your own emails here’s one thing you can try: use your existing sending infrastructure to send a bare-bones “Hello World” email and see if the red banner shows up or not. If it doesn’t, then, presumably, something inside your regular email body is triggering it. Selectively remove chunks of the content until you find the problematic element. Change it or remove it.
It is also important to do the other things: set up and validate SPF and DMARC records, test your unsubscribe links, monitor the bounce and complaint rates, monitor email blacklists, etc.
Good luck!
Pēteris,
https://hashrocket.com/blog/posts/working-with-email-addresses-in-postgresql#fn4
Working with Email Addresses in PostgreSQL
by Josh Branchaud on May 2, 2016
Most of the data we work with day to day is not case-insensitive. For the data that is though, we need to check our assumptions. Is our database enforcing the constraints we think? Do we understand where our indexes are working for us and, more importantly, where they are not?
The more verbose title for this post would read, "Working With Email Addresses And Other Case-Insensitive Data In PostgreSQL". This is to say that while the rest of this post will focus on the email address example, the concepts will generally apply to anything you consider to be case-insensitive.
When working with email addresses from a database perspective, there are a few things I'd like to keep in mind.
First, an email address is generally used to identify a user. Because of this, I'd like the database to ensure the uniqueness of stored email addresses.
Second, email addresses should be treated as case-insensitive. JACK@nbc.com and jack@nbc.com should be handled as the same email address. This is important for scenarios like a user logging in where I cannot assume how they will capitalize their email address.
Third, the email column in my database will be accessed frequently. For instance, every time someone signs in, I find the user record by email address and then verify the given password. The database should be able to do lookups on the email column efficiently.
In brief, I'd like the database to provide efficient lookups of a unique email column.
Setup
With that in mind, let's do some initial setup.
create table users (
id serial primary key,
email text not null unique,
password_digest text not null
);
insert into users (email, password_digest)
select
'person' || num || '@example.com',
md5('password' || num)
from generate_series(1,10000) as num;
This abbreviated table is representative of what I usually see for users tables storing email addresses1.
Here is a look at the table's description:
\d users
Table "public.users"
Column | Type | Modifiers
-----------------+---------+----------------------------------------------------
id | integer | not null default nextval('users_id_seq'::regclass)
email | text | not null
password_digest | text | not null
Indexes:
"users_pkey" PRIMARY KEY, btree (id)
"users_email_key" UNIQUE CONSTRAINT, btree (email)
The email column has a unique constraint, which should cover our unique email addresses requirement, with a btree index, that will help with efficient lookups. That should cover it.
The Catch
This post isn't quite over though because, unfortunately, it isn't that easy.
First, we aren't really preventing duplicates. The first record in the table is person1@example.com. I can easily insert another record with a duplicate email address:
insert into users (email, password_digest)
values ('Person1@example.com', md5('password'));
And inserted. All I had to do was change the casing.
The unique constraint is only constraining the email column to a case-sensitive uniqueness. For email addresses, person1@example.com and Person1@example.com should be treated as identical.
These kinds of issues are especially likely if we are working with an ORM, such as the one provided by ActiveRecord. Though ORMs provide lots of convenience, they can hide the important details of the database and ultimately lead us to believe our database schema is tighter than it actually is2.
We'll have to update our constraint, but first let's explore the lookup efficiency.
We don't care if the user enters person1@example.com or PERSON1@EXAMPLE.COM when signing in, we want our application to handle it the same. This is key to providing consistent lookup of user records. We need a way to look at email addresses in a case-insensitive way.
Let's use PostgreSQL's lower() function for that.
select * from users where lower(email) = lower('PERSON5000@EXAMPLE.COM');
-- id | email | password_digest
-- ------+------------------------+----------------------------------
-- 5000 | person5000@example.com | 81aa45be581a3b21e6ff4da69b8c5a15
Despite the casing not matching, we are able to find the record. If we look at the explain analyze output, though, we'll see a problem.
explain analyze select * from users where lower(email) = lower('PERSON5000@EXAMPLE.COM');
-- QUERY PLAN
-- ----------------------------------------------------------------------------------------------------
-- Seq Scan on users (cost=0.00..264.00 rows=50 width=59) (actual time=5.784..11.176 rows=1 loops=1)
-- Filter: (lower(email) = 'person5000@example.com'::text)
-- Rows Removed by Filter: 10000
-- Planning time: 0.108 ms
-- Execution time: 11.243 ms
Postgres ends up doing a sequential scan of the users table. In other words, it is not using the users_email_key index. In order to provide a consistent lookup via the lower() function, we have lost the speed benefits of our index.
We've gone from feeling pretty good about our index to realizing that it both allows duplicates and cannot provide both consistent and efficient lookups on the email column.
We can remedy this, though.
A Better Index
We plan to almost exclusively do user email address lookups in conjunction with the lower() function. So, what we need is a functional index; one that indexes the email column with lower(). If we also make this a unique index, then we will have constrained the email column to email addresses that are unique after the lower() function has been applied to them3.
This will solve both of our problems. Let's add it.
We still have that duplicate record (Person1@example.com), so the first thing we want to do is clean that up (and anything else that will violate the upcoming index).
delete from users where email = 'Person1@example.com';
We can then use the create index command to add this better index:
create unique index users_unique_lower_email_idx on users (lower(email));
Because the index uses the lower() function, we call it a functional index.
We can see the new index by taking another look at the users table's description:
\d users
Table "public.users"
Column | Type | Modifiers
-----------------+---------+----------------------------------------------------
id | integer | not null default nextval('users_id_seq'::regclass)
email | text | not null
password_digest | text | not null
Indexes:
"users_pkey" PRIMARY KEY, btree (id)
"users_email_key" UNIQUE CONSTRAINT, btree (email)
"users_unique_lower_email_idx" UNIQUE, btree (lower(email))
If we try to insert a duplicate record like we did earlier, Postgres will throw up a red flag.
insert into users (email, password_digest) values ('Person1@example.com', md5('password'));
-- ERROR: duplicate key value violates unique constraint "users_unique_lower_email_idx"
-- DETAIL: Key (lower(email))=(person1@example.com) already exists.
Fantastic.
We can also use explain analyze again to get some insight into the performance with our new index:
explain analyze select * from users where lower(email) = lower('PERSON5000@example.com');
-- QUERY PLAN
-- -------------------------------------------------------------------------------------------------------------------------------------
-- Index Scan using users_unique_lower_email_idx on users (cost=0.29..8.30 rows=1 width=59) (actual time=0.051..0.052 rows=1 loops=1)
-- Index Cond: (lower(email) = 'person5000@example.com'::text)
-- Planning time: 0.134 ms
-- Execution time: 0.082 ms
The part to focus on is the first line under QUERY PLAN. Earlier this same query necessitated a full sequential scan. Now, Postgres is able to do an Index Scan using users_unique_lower_email_idx. This gives us performant, consistent lookups4.
Another Approach
The citext module gives us another approach to this issue of handling case-insensitive data.
The
citextmodule provides a case-insensitive character string type, citext. Essentially, it internally calls lower when comparing values. Otherwise, it behaves almost exactly like text.
By declaring our email column with the citext type instead of text or varchar, we get the same benefits as the previous section without the additional index.
Taking the citext approach, we would create a table like the following:
create extension citext;
create table users (
id serial primary key,
email citext not null unique,
password_digest varchar not null
);
\d users
Table "public.users"
Column | Type | Modifiers
-----------------+-------------------+----------------------------------------------------
id | integer | not null default nextval('users_id_seq'::regclass)
email | citext | not null
password_digest | character varying | not null
Indexes:
"users_pkey" PRIMARY KEY, btree (id)
"users_email_key" UNIQUE CONSTRAINT, btree (email)
There are a few benefits to using citext. We have less hoops to jump through because we no longer need to setup an additional index and we don't have to include lower() on both sides of every comparison. We also get some performance gain on writes by reducing the number of indexes we have to update by one.
The main benefit for me is being able to write a case-insensitive lookup like we would any other statement:
select * from users where email = 'PERSON5000@example.com';
id | email | password_digest
------+------------------------+----------------------------------
5000 | person5000@example.com | 81aa45be581a3b21e6ff4da69b8c5a15
And if you are to check the explain analyze, you'll see that it is able to perform an index scan5.
In Summary
When it comes to case-insensitive data like email addresses, you now understand how to enforce uniqueness and get efficient lookups. Perhaps you are even considering moving from text to citext. I hope you are also a bit more wary of what your application framework's ORM is doing for you as well as what database-level details it is hiding from you.
I assume some level of ubiquitousness because this is the column definition and index provided by the Devise gem.
You may have application-level uniqueness validations (a la Devise), but I'd argue that's not good enough. Your database should have the final say when it comes to preventing invalid and inconsistent data. This is an especially important point in a tech landscape that is often embracing microservices and multiple application clients (i.e. web, iOS, android).
Why don't we just lowercase all email addresses before inserting them or querying for them? Well, that is yet another thing we have to remember to do at every access point to our database. It's easier to let an index do it. Less cognitive overhead as well.
I am going to leave our old index (users_email_key) on the table. Though I expect the lower(email)-style query to be most common, I still assume there will be the occasional query on email by itself. I'd still like the benefits of the query. I can tolerate the very minor overhead of maintaining two indexes on a read-heavy table.
There are some limitations to the citext module that you may never run up against, but are worth knowing about. They are detailed in the Limitations section of the docs for citext.
https://mitelman.engineering/blog/python-best-practice/automating-python-best-practices-for-a-new-project/
Python Best Practices for a New Project in 2021
Alex Mitelman, 2020, Oct 18
Intro
The goal of this tutorial is to describe Python development ecosystem. It can be helpful for someone coming to Python from another programming language.
They say that you should stick to algorithms and data structures, that you can learn a new language in just a couple of weeks, that it’s just a new syntax. I completely agree that algorithms and data structures are extremely important but when it comes to language it’s slightly more than just syntax. There is an entire infrastructure of tools and best practices around it. For someone coming from a different background, it can be overwhelming to keep up with all this stuff, especially taking into consideration that sometimes information should be found in different places.
This is my very opinionated attempt to compile some of the best practices on setting up a new Python environment for local development. There are also advices for integration these tools with Visual Studio Code, however, it’s not necessary to use this particular editor. I’m going to update this page as there are some changes with the underlying tools. I also plan to use it myself as a boilerplate for starting a new Python project. The tutorial is long because I explain in detail purpose and usage of the tools, however, the end result is quick set up of the new project environment that can be achieved in just a couple of minutes. See Fast Track section.
How to manage Python versions with pyenv?
Why use pyenv?
Many tutorials start with the same thing: go to python.org and download the latest version of the language for you platform. Don’t listen to them. There is a better way. And here is why.
There are different versions of Python and you would need switching between these versions while working on different projects.
There is probably some version of Python already coming with your operation system. For Mac it’s 2.7, some Linux distributions already switched to version 3. Even more, there is another Python installed as a part of Anaconda package. The bottom line is: you never know for sure which Python is going to be run as you type python in the command line.
At some point, there’s going to be a mess of different Python executables on your machine, and you will need some way of managing it. If only there was a tool for that.
And there is. It’s called pyenv - https://github.com/pyenv/pyenv
How to install pyenv?
Install for Mac:
brew update
brew install pyenv
For Linux you’d probably better off with pyenv installer - https://github.com/pyenv/pyenv-installer:
curl https://pyenv.run | bash
For Windows, there is pyenv for Windows - https://github.com/pyenv-win/pyenv-win.
But you’d probably better off with Windows Subsystem for Linux (WSL), then installing it the Linux way.
How to use pyenv? First, we can see a list of all Python executables, if any, that are installed on your machine (at least the ones pyenv was able to find):
pyenv versions
* system (set by /Users/alex/.python-version)
Above shown the output for my machine. Here asterisk indicates the current active version of Python. So if I run
python -V
Python 2.7.16
we can see that MacOS is still shipped with Python 2.7 as a system executable.
Now let’s see all the available Python versions:
pyenv install --list
This will output a long list of different Python versions. You will be surprised how many Pythons there are. CPython implementations default to versions like 3.8.5, other have prefixes like pypy3.6-7.3.1.
If you want to see only CPython version, you can run something like this:
pyenv install --list | grep " 3\."
If you are using pyenv for quite some time, and there is no new version in the list, you should update pyenv itself:
brew upgrade pyenv
or
pyenv update
Versions with suffix -dev are currently in active development.
Let’s install the most new and stable Python version to the moment of writing this post
pyenv install 3.8.5
This downloads the source code and compiles it on your machine:
python-build: use openssl@1.1 from homebrew
python-build: use readline from homebrew
Downloading Python-3.8.5.tar.xz...
-> https://www.python.org/ftp/python/3.8.5/Python-3.8.5.tar.xz
Installing Python-3.8.5...
python-build: use readline from homebrew
python-build: use zlib from xcode sdk
Installed Python-3.8.5 to /Users/alex/.pyenv/versions/3.8.5
If we run pyenv versions again, we see our new version in the list but it’s still not active
* system (set by /Users/alex/.python-version)
3.8.5
We can verify it with python -V. Still
Python 2.7.16
pyenv allows us to set up any version of Python as a global Python interpreter but we are not going to do that. There can be some scripts or other programs that rely on the default interpreter, so we don’t want to mess that up. Instead, we are going to set up Python per project. So let’s create a project in the next section.
Alternative tool: asdf: https://asdf-vm.com/
Dependency management for Python with Poetry
Why use Poetry?
By default, Python packages are installed with pip install. In reality nobody uses it this way. It installs all your dependencies into one version of Python interpreter which messes up dependencies.
It’s a good practice to install dependencies per project. So each project only contains dependencies that are required for it, and nothing more. This also prevents conflicts of versions of different packages that are required for different projects.
To solve this problem, there is a concept of virtual environments. So each project has it’s own virtual environment with fixed Python version and fixed dependencies specific for this project.
Virtual environments evolved from venv, virtualenv, virtualenvwrapper to pipenv, and poetry. pipenv is very popular and was a good choice for a long time. There was some controversy about pipenv that is greatly covered by this blog post: Pipenv: promises a lot, delivers very little by Chris Warrick. One of the biggest concerns was delay in releases - there was no new release since 2018. Although, mid 2020 pipenv became active again with several new updates, lots of developers made up their mind already. Poetry gained some traction, in addition it claims to better resolve dependencies where pipenv fails. Also, Poetry can be helpful for open source projects as it helps publishing the package.
Poetry official website: https://python-poetry.org/
How to install Poetry?
So, let’s get it started. It is recommended to install Poetry on a system level.
For MacOS, Linux, and WSL:
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python
If you use Powershell with Windows, there is a script for that on the official website but I personally suggest just using WSL.
To apply changes for your current shell session, run
source $HOME/.poetry/env
You may add this to the auto-run shell script like .bashrc or .zshrc if Poetry doesn’t appear in a new shell session:
export PATH="$HOME/.poetry/bin:$PATH"
You can also enable tab completions for your shell. The process is described here.
How to create new project with Poetry?
Poetry creates a folder structure for you, so make sure to change your current directory to one that is supposed to be a parent directory for the new project and then run:
poetry new my-project
where my-project is the name of the project. Put a name of your project instead.
Now, let’s see what Poetry created for us:
cd my-project; ls
How to set Python version per project?
We were still using old Python 2.7, remember? For our new project, we want to use modern version of Python, so we are back to pyenv tool. As we are still in the project directory, set Python version locally for this directory:
pyenv local 3.8.5
If we run pyenv versions now, we can see that 3.8.5 is marked with asterisk, so it’s active for this directory. Note that outside of this directory Python version remains the same as before.
system
* 3.8.5 (set by /Users/alex/iCloud/dev/projects/my-project/.python-version)
We can double check it with python -V.
Python 3.8.5
Now we make Poetry pick up current Python version:
poetry env use python
Creating virtualenv my-project-PSaGJAu6-py3.8 in /Users/alex/Library/Caches/pypoetry/virtualenvs
Using virtualenv: /Users/alex/Library/Caches/pypoetry/virtualenvs/my-project-PSaGJAu6-py3.8
As the last step of setting up Python version, let’s update pyproject.toml. [tool.poetry.dependencies] should reflect that supported version of Python is 3.8 or higher:
[tool.poetry]
name = "my-project"
version = "0.1.0"
description = ""
authors = ["Alex"]
[tool.poetry.dependencies]
python = "^3.8"
[tool.poetry.dev-dependencies]
pytest = "^5.2"
[build-system]
requires = ["poetry-core>=1.0.0a5"]
build-backend = "poetry.core.masonry.api"
How to use Poetry?
On the next step, you probably want to install your first dependency: some library or framework on top of which you plan to build the project. For example:
poetry add aiohttp
where aiohttp is the framework we install.
If you pull an existing project and want to install its dependencies for local development, simply run
poetry install
To bump all the dependencies to the latest versions:
poetry update
How to use Poetry with VS Code?
VS Code doesn’t detect Poetry automatically. Good news though, there is a simple way to make VS Code detect virtual environment created by Poetry.
First, we have to activate virtual environment:
poetry shell
Spawning shell within /Users/alex/Library/Caches/pypoetry/virtualenvs/my-project-PSaGJAu6-py3.8
➜ my-project . /Users/alex/Library/Caches/pypoetry/virtualenvs/my-project-PSaGJAu6-py3.8/bin/activate
(my-project-PSaGJAu6-py3.8) ➜ my-project
So now, as we are inside said virtual environment, we can call VS Code from it:
code .
Install Pylance - Python language server for VS Code.
As you open any Python file, VS Code immediately asks us to choose a Python interpreter

So let’s do exactly what we were asked. Because we called VS Code from within the virtual environment, the right interpreter will be presented as an option and we can choose it.
Notice that there are two options for 3.8.5, we should select the one that sits under virtual environment (see file path, it should contain virtualenv).
In general, you can like this Github issue to add support for Poetry to VS Code: https://github.com/microsoft/vscode-python/issues/8372 to keep track of the progress. As Brett Cannon said, VS Code team is reworking environment discovery code, so eventually Poetry will be fully supported by VS Code.
How to upgrade Poetry?
Simply running poetry self update will bump to the most recent version of Poetry.
If you run into error
ImportError: No module named cleo
you’d need to reinstall Poetry by removing it first:
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py > get-poetry.py
python get-poetry.py --uninstall
python get-poetry.py
rm get-poetry.py
How to upgrade Python version with Poetry and pyenv?
Time has passed and the new Python version was released. There are new features and bugfixes, so we want to bump Python version in our project. This is a pretty straightforward task for pyenv and Poetry.
First, we download, compile and set up the new Python interpreter. Make sure to run this command not from virtual environment but from the project root folder. In my case, I’m going to upgrade to CPython 3.9.2 which is available at the time of writing this text but it can be any other version of CPython interpreter.
pyenv install 3.9.2
pyenv local 3.9.2
pyenv versions
my-project pyenv versions
system
3.8.5
* 3.9.2 (set by /Users/alex/iCloud/dev/projects/my-project/.python-version)
Next, we make Poetry use this interpreter for virtual environments.
poetry env use python
Creating virtualenv my-project-PSaGJAu6-py3.9 in /Users/alex.mitelman/Library/Caches/pypoetry/virtualenvs
Using virtualenv: /Users/alex/Library/Caches/pypoetry/virtualenvs/my-project-PSaGJAu6-py3.9
Notice that the project hash remains the same as before but the Python version is now 3.9.
As we have a new virtual environment, we have to reinstall all the dependencies for it:
poetry install
On the next step, we just activate virtual environment and double check that the right version of Python was picked up. We also start VS Code from within the virtual environment, so it is able to discover new environment (make sure to close VS Code before that).
poetry shell
python -V
code .
Finally, at the bottom left corner click on Python and choose the updated version from the list. Make sure that you pick virtual environment version.

The above images show version 3.9.0 that was used for the previous version of the article
Don’t forget to update [tool.poetry.dependencies] section in pyproject.toml file to reflect the Python version support.
VS Code will prompt you to choose linter, code formatter, etc. Please ignore those prompts for now. We will set them up later on in this tutorial.
Alternative: venv - built in with Python.
How to test with pytest?
Why use pytest?
Tests are important, so first thing we do after creating the project is taking care of tests.
pytest is a popular framework that received a broad adoption. In fact, it’s so popular, that it comes as a default testing framework for Poetry. So if we open [tool.poetry.dev-dependencies] section in pyproject.toml we can see that pytest is already listed there as a development dependency.
More than that, Poetry created tests folder structure for us.
cd tests; ls
__init__.py __pycache__ test_my_project.py
How to use pytest with VS Code?
As an intentionally oversimplified example, let’s create and test function that multiplies two numbers. According to TDD, we create test first.
Let’s open test_my_project.py and add import of the function and very simple test:
from my_project.math import multiply_two_numbers
def test_multiply_two_numbers():
result = multiply_two_numbers(2, 3)
assert result == 6
Instead of running our tests from the terminal, let’s take advantage of code editor. ⇧⌘P - start typing “Python: Discover Tests” and select it from the dropdown. (Keybord shortcuts here and further are for macOS)

Test framework selection appears in the bottom right corner. Click the button:

and select pytest in the dropdown:
As the last step, it asks you to provide directory that contains all your tests:
VS Code discovered our tests, so now it adds fancy buttons to run or debug particular test.
As we run tests with VS Code, it obviously marks them red as we didn’t implement the function yet.

So let’s create math.py file in my_project directory and then implement our simple function:
def multiply_two_numbers(a, b):
return a * b
As we run tests again, they are marked green now

Alternatively, you can run tests from the command line with
poetry run pytest
or from the activated virtual environment just
pytest
Alternative: unittest - included with default Python distribution. Disadvantages: non-Pythonic camelcase API, slightly harder syntax.
How to measure tests coverage with pytest-cov?
Where tests, there’s coverage. We can install pytest-cov plugin for pytest to measure tests coverage:
poetry add --dev pytest-cov
Now running tests with an additional parameter will generate a coverage report:
pytest --cov=my_project tests/
================================================= test session starts =============
platform darwin -- Python 3.9.2, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
rootdir: /Users/alex/iCloud/dev/projects/my-project
plugins: cov-2.10.1
collected 2 items
tests/test_my_project.py .. [100%]
----------- coverage: platform darwin, python 3.9.2 -----------
Name Stmts Miss Cover
--------------------------------------------
my_project/__init__.py 1 0 100%
my_project/math.py 4 0 100%
--------------------------------------------
TOTAL 5 0 100%
================================================== 2 passed in 0.08s ===============
This also generates .coverage file which we don’t want in our version control, so let’s not forget to add it .gitignore:
echo '.coverage' > .gitignore
How to run checks before committing changes with pre-commit?
Use Git
We didn’t talk about version control yet, and we should. Obviously, we are using Git in 2021. Install or update to the latest version. For macOS:
brew install git
If there is no repository for the project yet, we should create it. Github creates new repositories with main default branch now, so let’s create it this way too:
git init -b main
First thing first, we should have .gitignore file, so we don’t commit some temporary or binary files to the repo. We can manually copy-paste it from here https://github.com/github/gitignore/blob/master/Python.gitignore or simply run following command which will create .gitignore and download content of the above link into it. You must be in your project root directory.
curl -s https://raw.githubusercontent.com/github/gitignore/master/Python.gitignore >> .gitignore
You may exclude VS Code settings folder from version control. In addition, we may also exclude PyCharm settings if someone uses that code editor.
echo '.vscode/\n.idea/' >> .gitignore
Same way
Now let’s add everything we have so far to version control:
git add .
Why run checks before commit? As you can see (and will see further down in the tutorial), the boilerplate for the project is big. It’s easy to miss out on something or forget to apply some checks before committing your code to the remote repo. As a consequence, the code will not pass CI automation, your colleagues or maintainers may ask you to make some changes to the code during the code review. All this because of a small nitpick like absence of a newline character at the end of a file. Having newline there is a POSIX standard. Even if you are well aware of that, it’s very easy to forget or miss out on this. All this back and forth is just a waste of time which could be easily avoided if there was some automation before we commit a piece of code. And there is.
Please welcome pre-commit. It’s a tool to run automatic checks on every git commit. It’s easy to use and it doesn’t require root access. By the way, pre-commit is written in Python but can be used for projects in various programming languages.
How to install and use pre-commit?
pre-commit can be installed on a system level but we don’t want to do that exactly for the reasons we started using pyenv - we are going to use different Python versions and our dependencies should be in order. That’s why we install pre-commit as a development dependency:
poetry add pre-commit --dev
Going forward we will put all our linters and other stuff into the pre-commit hook. For the time being, we are going to create a simple config for small stuff like end of file newline that we discussed as an example.
There is a command for pre-commit to conveniently create a sample file for us. Executed from our project root:
pre-commit sample-config > .pre-commit-config.yaml
it creates a config file with the following content:
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v2.4.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
We can see that pre-commit already created some handy hooks for us. Let’s see how it works. To run checks manually:
pre-commit run --all-files
After running pre-commit, it already found that even file that was created by VS Code didn’t contain newline at the end!
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Failed
- hook id: end-of-file-fixer
- exit code: 1
- files were modified by this hook
Fixing my_project/math.py
Fixing .vscode/settings.json
Fixing tests/test_my_project.py
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
pre-commit actually fixed that for us, so if we run the same command again, all checks are passed OK.
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
The most important part is to make Git aware of these hooks and to run them before each commit.
pre-commit install
pre-commit installed at .git/hooks/pre-commit
Now, we can commit changes:
git commit -m 'Initial commit'
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
[master (root-commit) 7dc335f] Initial commit
11 files changed, 559 insertions(+)
create mode 100644 .gitignore
create mode 100644 .pre-commit-config.yaml
create mode 100644 .python-version
create mode 100644 .vscode/settings.json
create mode 100644 README.rst
create mode 100644 my_project/__init__.py
create mode 100644 my_project/math.py
create mode 100644 poetry.lock
create mode 100644 pyproject.toml
create mode 100644 tests/__init__.py
create mode 100644 tests/test_my_project.py
As we can see, hooks were run before the commit. Just as planned.
One last thing, we can ask pre-commit to keep config updated to the latest version of tools:
pre-commit autoupdate
It immediately updates hook for me:
Updating https://github.com/pre-commit/pre-commit-hooks ... updating
Code analysis with Flake8 linter
Why use linter for Python project?
Linters are on the front line of the fight with errors and bugs. They signal you even before you run the code. Obviously, IDEs support linters, so you don’t even have to run the manually. IDE with the help of linter can flag wrong code right in the moment you actually write it.
In Python world, there are lots of linters but two major ones are Flake8 and Pylint.
Pylint is a very strict and nit-picky linter. Google uses it for their Python projects internally according to their guidelines. Because of it’s nature, you’ll probably spend a lot of time fighting or configuring it. Which is maybe not bad, by the way. Outcome of such strictness can be a safer code, however, as a consequence - longer development time.
Most popular open source projects use Flake8. But before we start, there is another hero in the Python world we should talk about.
Python Style Guide - PEP8
Python Style Guide, more famous by it’s Python Enhancement Proposal number- PEP8. Every Python developer should get themselves familiar with PEP8, along with Zen of Python (PEP 20).
After reading through PEP8, you may wonder if there is a way to automatically check and enforce these guidelines? Flake8 does exactly this, and a bit more. It works out of the box, and can be configured in case you want to change some specific settings.
While it’s not as strict as Pylint, it still does a great job on a first line of defense.
That’s why I recommend sticking to Flake8. You can still use Pylint as a second linter but Flake8 is a bare minimum.
How to install Flake8?
VS Code will prompt you to select linter for the project. You can also press ⇧⌘P, start typing “linter” and choose “Python: Select Linter”

Then choose “flake8”s
VS Code should pick up your virtual environment and install Flake8 as a development dependency.
If it doesn’t happen or if you want to install it from the command line, here is a way:
poetry add flake8 --dev
How to use Flake8?
Getting back to a small portion of the code we wrote in a previous section. VS Code marks red some code that linter found problem with. By setting a pointer to that part we can see an error message, error number (that we can search on the internet), and the linter that flagged the error.
We can also run Flake8 manually to see the same result:
flake8 .
./tests/test_my_project.py:4:1: E302 expected 2 blank lines, found 1
./tests/test_my_project.py:7:1: E302 expected 2 blank lines, found 1
How to add Flake8 to git hooks?
Red marks in IDE is easy to ignore sometimes. It’s also easy to forget running flake8 command before submitting our code. That’s why we have git hooks. We can add Flake8 to the hooks list, so it will check our code with linter automatically.
To do this, open .pre-commit-config.yaml and add following:
- repo: https://gitlab.com/pycqa/flake8
rev: 3.8.3
hooks:
- id: flake8
Pay extra attention to rev line. I’ve added version myself here. To figure out version of Flake8 we currently use, I opened pyproject.toml, found version of Flake8, and put it in the pre-commit config file as stated above.
Remember, as we asked pre-commit to keep versions up to date, it would update Flake8 to the most recent version. But as we already use the newest version of the linter, nothing extra will be done here. pre-commit will download this version of Flake8 because it runs its checks in the separate environment. This means that we basically have two versions of Flake8 now, and we should make sure that they are actually the same version. Usually updating to the latest version shouldn’t be an issue but if it is, it’s recommended to turn auto update off for pre-commit.
As we change config file, let’s stage it:
git add .pre-commit-config.yaml
And commit:
git commit -m 'Add Flake8 to git hooks'
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
flake8...............................................(no files to check)Skipped
[master 1d25c9f] Add Flake8 to git hooks
1 file changed, 4 insertions(+)
Let’s try running pre-commit manually again to see how it picked up Flake8:
pre-commit run --all-files
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
flake8...................................................................Failed
- hook id: flake8
- exit code: 1
tests/test_my_project.py:4:1: E302 expected 2 blank lines, found 1
tests/test_my_project.py:7:1: E302 expected 2 blank lines, found 1
Don’t hurry fixing this error to satisfy the linter. Computer already found the error. If it’s already of it, wouldn’t it be great to fix this error automatically?
Formatting code with Black
Why to format code with Black?
Every person writes code in their own style. Even on Python which forces you pretty much to indent blocks of code, it is very much possible to write the same thing in different ways.
Sometimes, just by looking at some part of code, you could say what person wrote it. What if different people touched the same code and wrote different parts of it in their own style? It can look a bit ugly.
How can we prevent it? We can argue during the code review of course. This can significantly slow down merging such pull request. Also, arguing about style is pretty much a matter of taste. At the end of the day, people will argue about the looks instead of paying attention to what the code actually does.
In addition, wouldn’t it be nice if code looked the same across an entire project, just like it was written by one person?
There is a solution for it, and it’s called Black.
Black formats the code in its own style, so it looks consistent. There is very little that you can customize in Black, so even this case there is no room for an argument. Just take it and use it as it is. After all, things like PEP8 and Black were created to agree on one style and just stop arguing about it.
Ironically, Black violates PEP8’s line length rule. Here is a thing, PEP8 told us that the maximum line length should be no more than 79 characters. It goes deep into history of IBM punch cards and UNIX terminals. PEP8 was written in 2001, things changed since then. People started questioning this rule. “I don’t read the code from a UNIX terminal”, - they say. “I have 27” monitor for a reason", - they say. There is a problem with that though. Some people work with code from 13" laptops. And viewing diff of two files of 79 char per line max becomes very convenient. Otherwise, you have to scroll horizontally, which is not very nice for working with code. That’s why I still think that 79 chars rule should be there.
And yes, while PEP8 was created in 2001, it’s received some updates since then but 79 char per line rule was never changed.
Thankfully, this is an option that Black allows us to adjust.
###How to install Black?
In VS Code, open some Python file in our project. In my case, I have test_my_project.py that Flake8 was complaining about. ⇧⌘P and start typing “format”, then choose “Format Document”.
It will ask you which formatter would you like to use.

Click “Use black”.
VS Code will detect that we use Poetry and will install Black for us automatically.

Optionally, you can install it manually with:
poetry add --dev black --allow-prereleases
--allow-prereleases option is here because Black is actually still in Beta in 2021. Initially, 2019 releases were planned to be the last ones in this status but it is what it is. Many production and open source projects already use it by default to format the code, so it’s pretty safe to assume that Black is relatively stable.
To configure Black, let’s open pyproject.toml and add following section:
[tool.black]
line-length = 79
target-version = ['py38']
include = '\.pyi?$'
exclude = '''
(
/(
\.eggs # exclude a few common directories in the
| \.git # root of the project
| \.hg
| \.mypy_cache
| \.tox
| \.venv
| _build
| buck-out
| build
| dist
)/
| foo.py # also separately exclude a file named foo.py in
# the root of the project
)
'''
The most important part here is that we set max line length to 79.
Also, if you use some other version of Python, make sure to update but double check that it’s supported by Black here.
We also have to suppress some error at Flake8 to make it work with Black. For this, we have to create setup.cfg file, which is a config file for Flake8, and put following in there:
[flake8]
extend-ignore = E203
How to use Black?
Black usage is fairly simple. Just run it, and it formats the code:
black .
reformatted /projects/my-project/my_project/__init__.py
reformatted /projects/my-project/tests/test_my_project.py
All done! ✨ 🍰 ✨
2 files reformatted, 2 files left unchanged.
Remember Flake8 was complaining about some absent new lines? If we run our Git hook now, everything is OK.
pre-commit run --all-files
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
flake8...................................................................Passed
How to add Black to git hooks?
Same as with Flake8, it would be great to automate running Black, so we don’t have to bother. Let’s add following to .pre-commit-config.yaml
- repo: https://github.com/psf/black
rev: 20.8b1
hooks:
- id: black
Let’s run pre-commit run --all-files again. We can see that it downloads Black and uses it:
[INFO] Initializing environment for https://github.com/psf/black.
[INFO] Installing environment for https://github.com/psf/black.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
flake8...................................................................Passed
black....................................................................Passed
I will not describe saving changes to git. The flow is the same as for Flake8.
Alternative: yapf - https://github.com/google/yapf
Bonus
You can add ruler to VS Code so there is a vertical line showing you the edge of 79 characters.
Open settings.json in .vscode directory and add following:
"[python]": {
"editor.rulers": [72, 79]
}
This will add rulers only for Python. 72 chars is for docstrings.
Static typing with Mypy
Why use static type checker with Python?
Type wars started in 70s. IBM with Smalltalk against Sun with Java. As we all know, strongly typed Java won, although Smalltalk being dynamically typed language was considered as a competitive advantage by some companies due to rapid development. Of course, type reduces amount of bugs and runtime errors which can be also solved by having 100% test coverage (as Uncle Bob claims, that’s one of the reasons of Python’s success). However, let’s not forget that not all projects have 100% coverage.
But can we have best of two worlds? Can we have type safety with rapid software development? I think, with Mypy we can. Mypy is a static code analysis tool that makes sure that the code is type safe. The project became so valuable that Python creator Guido van Rossum added type annotations to Python and joined Mypy development. Using type annotations also helps IDE to provide a better code completion. As a bonus, type annotations make code more readable for humans too.
How to install mypy
In VS Code, you can edit settings.json file in .vscode directory. Set "python.linting.mypyEnabled": true. After that, open any Python file in the project, for example math.py. VS Code will detect that Mypy is not installed yet.
Click install, and it will automatically install it with Poetry.
Alternatively, you can install Mypy manually:
poetry add --dev mypy
How to use mypy?
Now we can try running this tool on our small project:
mypy .
Success: no issues found in 4 source files
So far so good, we didn’t even have to make any changes to our code, Mypy automatically detects types to run checks.
But as we mentioned previously, having type annotations helps us better understand code, and makes IDE provide better code completions, so let’s take advantage of that.
Open setup.cfg file and add following:
[mypy]
follow_imports = silent
strict_optional = True
warn_redundant_casts = True
warn_unused_ignores = True
disallow_any_generics = True
check_untyped_defs = True
no_implicit_reexport = True
disallow_untyped_defs = True
ignore_missing_imports = True
The most important line here is disallow_untyped_defs = True. It forces you to define functions with types. For existing legacy projects, you’d probably disable it but as we create a new project, it’s would be beneficial to make sure we never forget to add type annotations.
You may want to disable Mypy for tests. Just add following config:
[mypy-tests.*]
ignore_errors = True
For better compatibility, there are various plugins for Mypy. For example, if you plan to use pydantic for data validation and serialization, config file will look like this:
[mypy]
plugins = pydantic.mypy
follow_imports = silent
strict_optional = True
warn_redundant_casts = True
warn_unused_ignores = True
disallow_any_generics = True
check_untyped_defs = True
no_implicit_reexport = True
disallow_untyped_defs = True
ignore_missing_imports = True
[pydantic-mypy]
init_forbid_extra = True
init_typed = True
warn_required_dynamic_aliases = True
warn_untyped_fields = True
Here is the output after we added new config:
my_project/math.py:1: error: Function is missing a type annotation
Found 1 errors in 1 files (checked 4 source files)
In addition, VS Code uses Mypy as a linter and marks incorrect parts:
To fix it, let’s add type annotation to our function:
from numbers import Real
from typing import Union
def multiply_two_numbers(a: Union[int, Real], b: Union[int, Real]) -> Union[int, Real]:
return a * b
As we can see, function definition got too long. By pressing ⇧⌥F , VS Code formats code with Black to make it fit into 79 characters per line:
from numbers import Real
from typing import Union
def multiply_two_numbers(
a: Union[int, Real], b: Union[int, Real]
) -> Union[int, Real]:
return a * b
Commit changes:
git commit -m 'Add Mypy'
How to add mypy to git hooks?
Obviously, we want to make sure that Mypy runs before committing the code. Add following to .pre-commit-config.yaml:
- repo: https://github.com/pre-commit/mirrors-mypy
rev: v0.782
hooks:
- id: mypy
additional_dependencies: [pydantic] # add if use pydantic
As we run pre-commit run --all-files it installs Mypy for pre-commits and runs checks:
[INFO] Installing environment for https://github.com/pre-commit/mirrors-mypy.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
flake8...................................................................Passed
black....................................................................Passed
mypy.....................................................................Passed
Sorting imports with isort
One last thing: imports.
Why sort imports isort?
PEP8 specifies that imports should be sorted in the following order: standard library, third party, local. In addition we want imports to be beautiful and human friendly.
And there is a tool for that. Meet isort which stands for “import sort”. Here is an example from official site to get a sense of it.
Before:
from my_lib import Object
import os
from my_lib import Object3
from my_lib import Object2
import sys
from third_party import lib15, lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8, lib9, lib10, lib11, lib12, lib13, lib14
import sys
from __future__ import absolute_import
from third_party import lib3
After:
from __future__ import absolute_import
import os
import sys
from third_party import (lib1, lib2, lib3, lib4, lib5, lib6, lib7, lib8,
lib9, lib10, lib11, lib12, lib13, lib14, lib15)
from my_lib import Object, Object2, Object3
Way better, isn’t it?
How to install, use, and add isort to git hooks?
VS Code (with Python extension) uses isort internally, so there is no additional configuration required. If you don’t plan to use it from the command line, there is even no need to install it separately because pre-commit installs all dependencies to its own separate environment.
But if you plan to use isort apart from VS Code and pre-commit, here is how to install it:
poetry add --dev isort
To make it works with Black correctly, we should add following to pyproject.toml:
[tool.isort]
multi_line_output = 3
include_trailing_comma = true
force_grid_wrap = 0
use_parentheses = true
line_length = 79
In VS Code, ⇧⌘P, then start typing “sort imports”. VS Code will show:
Alternatively, if you installed it, run in the project root:
isort .
Skipped 2 files
As a final step, let’s add it to the hooks list in .pre-commit-config.yaml:
- repo: https://github.com/PyCQA/isort
rev: 5.4.2
hooks:
- id: isort
See it works with pre-commit run --all-files:
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
flake8...................................................................Passed
black....................................................................Passed
mypy.....................................................................Passed
isort....................................................................Passed
Fast track
Here is how you can create a fully configured new project in a just a couple of minutes (assuming you have pyenv and poetry installed already).
poetry new my-project; cd my-project; ls
pyenv local 3.9.2
poetry env use python
poetry add --dev pytest-cov pre-commit flake8 mypy isort
poetry add --dev --allow-prereleases black
poetry shell
code .
Add config to pyproject.toml:
[tool.isort]
multi_line_output = 3
include_trailing_comma = true
force_grid_wrap = 0
use_parentheses = true
line_length = 79
[tool.black]
line-length = 79
target-version = ['py38']
include = '\.pyi?$'
exclude = '''
(
/(
\.eggs # exclude a few common directories in the
| \.git # root of the project
| \.hg
| \.mypy_cache
| \.tox
| \.venv
| _build
| buck-out
| build
| dist
)/
| foo.py # also separately exclude a file named foo.py in
# the root of the project
)
'''
Create setup.cfg:
[flake8]
extend-ignore = E203
[mypy]
follow_imports = silent
strict_optional = True
warn_redundant_casts = True
warn_unused_ignores = True
disallow_any_generics = True
check_untyped_defs = True
no_implicit_reexport = True
disallow_untyped_defs = True
ignore_missing_imports = True
[mypy-tests.*]
ignore_errors = True
Create .pre-commit-config.yaml.
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.4.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
- repo: https://gitlab.com/pycqa/flake8
rev: 3.8.4
hooks:
- id: flake8
- repo: https://github.com/psf/black
rev: 20.8b1
hooks:
- id: black
- repo: https://github.com/pre-commit/mirrors-mypy
rev: v0.812
hooks:
- id: mypy
additional_dependencies: [pydantic] # add if use pydantic
- repo: https://github.com/PyCQA/isort
rev: 5.7.0
hooks:
- id: isort
echo '.coverage' > .gitignore
echo '.vscode/\n.idea/' >> .gitignore
curl -s https://raw.githubusercontent.com/github/gitignore/master/Python.gitignore >> .gitignore
git init -b main
git add .
git commit -m 'Initial commit'
pre-commit install
pre-commit autoupdate
pre-commit run --all-files
pre-commit run --all-files
Conclusion
We’ve come a long way. Congrats if you’ve made it all the way from the beginning. I get that probably it was super overwhelming. The point of doing all this work is to set up a new project once and forget about it for a long time. For any further project it will be very quick, I promise. Just skip to Fast Track section, then it’s just a couple of minutes to set up all the necessary components. Now, it’s time to get our hands dirty with some actual code.
Interface Builder's Alternative Lisp timeline
Denison “Denny” Bollay is one of the guys at ExperTelligence that crafted the first Interface Builder (IB) and showed Steve Jobs and Bill Gates. Jeff Wishnie introduced me (thanks dude) recently, and I’ve been talking to Denny as I have an agenda - Pseudo-declarative UIs - that is in complete opposition to my patronage of AngularJS, but still UI markup related. As part of that agenda I’ve been trying to get to the bottom of a rumored version of Interface Builder (IB) that loaded and saved a Lisp ‘source’. I heard about this thing in the 90’s (can’t remember who told me) and I’ve been asking around about it ever since. ThoughtWorks has a number of Apple/NeXT alumni and coders active for 20+ years in the Mac space, so I’ve been able to explore more avenues.
Denny wrote “Action!” that was sold by Texas Instruments after his involvement with the precursor Lisp Interface Builder in 1986. Read on..
Action!
Here is a 15 minute ‘sales’ style video uploaded by Denny (and featuring him):
That’s: http://vimeo.com/62618532.
Denny has sorted through boxes in his garage looking for it, and I think it is a fun quarter of an hour for all.
This Texas Instruments video runs through the rationale for the genus of tool, then a demonstration of its use, a quicker list of features, and lastly some selling points.
Denny’s blurb that goes with the video (for those that did not click):
ExperTelligence introduced IB in 1986. We took it up to neXt to show Steve Jobs - the rest is history. In 1988, Denison Bollay built a much more dynamic interface tool, in which the interface was fully modifiable AS the program was running. Since it was built in incrementally compiled LISP, all other functions and methods were also modifiable on the fly. Denny took it to Seattle to show Bill Gates, but MicroSoft wanted a version written in basic (no objects, no methods, etc back then). I explained one couldn’t do that without OO. They built Visual Basic.
Sadly, it seems no one has duplicated Action!’s sophistication and interactivity even today, 25 years later!
Denny, Gray Clossman and (after relocation from France) JMH were all at ExperTelligence together and working on that IB. There was an intention to license Interface Builder as they had it, to NeXT. JMH going to NeXT and starting over on the same product was the end of that strategy. One of the realities of Californian IP law, much like Europe is that the ideas in your head, and your ability to rewrite something from concept, isn’t restrainable by your current/previous employer.
Markup formats
Binary Resource Forks (precursor IB)
The ExperTelligence team showed the first ExperLisp version of IB to Steve Jobs. Jobs was initially not sure whether the technology was an advance over HyperCard (also unreleased at that stage). Thirty minutes later, Jobs was a convert. Bill Gates was also shown (as mentioned) and Denny actually did that demo. This initial version of IB saved “resource forks” in binary in a Mac specified format. There’s a possibility that there was some brittleness to that over time, if library/framework/package/OS upgrades were considered. Binary was not inspectable or editable outside the IB toolchain.
NeXT and Apple’s versions
The first shipping version of IB from NeXT saved in .nib format. Some yeas later Apple changes this to .xib which is what we have today. The latter is human readable, source-control compatible, and if you’re insane - editable outside of the IB application.
Lisp (Action!)
Denny’s Action! saved in Lisp, and interpreted the same on load of the project. That was not just at design-time, but at runtime too. That was interpretation into a context, and a far cry from the parsing of XML, HTML, and XAML today.
This Action! derivative was made outside Apple/NeXT, and in conjunction with Texas Instruments. I can’t help but feel that Lisp is a better markup language that any of (chronological order) ‘serialized binary resource forks’, plists (.nib), XML (.xib), or even today’s HTML.
What’s not shown in the video is the markup code outside of the design tool. Specifically that Lisp DSL that could be round-trip edited in Vi/Emacs etc. Given this was a hopefully pretty-printed format of Lisp, I’ll claim it was source-control compatible from the outset. I hope Denny finds some example source and discusses it some more. To me, Action! is one the “holy grail” items from the history of user interfaces, if not Information Technology more generally.
Putting those together on a timeline
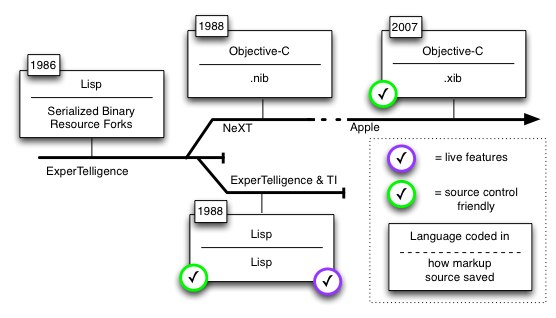
Versus the DOM?
I recently compared the DOM-mutating current cutting edge with the leased-rectangle types of UI layout/rendering. This Action! product from 1988, seems like something again that could speak directly to that space:
- A live mutable model of the objects within the UI (equiv of the DOM)
- An ability to flip from design mode to run quickly
- Considerations as to the types of affordances that were supportable
- Bindings to High level Languages (at least C++ back then)
Some differences too:
- No forward/back button
- No XPath style DOM traversal (only Lisp)
- no URL concept
- no lazy-loading page-by-page concept
- Not client server in the way the web is today
So the DOM of the modern HTML/CSS/JavaScript space is much more advanced given 25 more years, but you can’t help but contrast to the elegant beauty of a unified Lisp markup for the same (with a WYSIWYG editor). Not only contrast, but we could ponder ‘what if’.
1990 or thereabouts
Tim Berners-Lee, off in switzerland, used the NeXT version of Interface Builder to design the first web browser called WorldWideWeb initially, but later renamed to ‘Nexus’, before itself being obsoleted by Mosaic.
Denny was asked by the CIA to look into the forthcoming ‘web’. This was divulged after, I drew a parallel to the DOM as we have it today:
Tim Berners Lee only really spec’d HTTP and HTML in 91-93 [sic]. It was the Netscape guys that reverse engineered a DOM from that by 94-95. You might have been “there” earlier :)
Denny responded (I quote from his email):
Actually, that is another whole story. After seeing Action!, the CIA approached us in 1990(?) to discuss their work in the new fangled thing call “hypertext”. They had a contract with Xerox PARC, and had built “NoteCards” in LISP on a Xerox LISP machine. I re-architected the hypertext concepts to OO, with many classes of links unidirectional, bi-directional, contextual, searchable links and stored everything in an object database (written in LISP of course). We aptly called it “Dynamic Documents”. Another “lesson learned” was that people at Xerox had been hesitant to re-author all their docs, just so they could add links. We vastly improved this by allowing links between arbitrary portions of general purpose docs built in word processing apps, drawings, and databases. And, the links were “out of band” - so the docs & apps didn’t need to be changed. One day the CIA officer mentioned a project called the “web” in Switzerland, and gave us a copy of an HTML spec. We reviewed it with Xerox PARC at a “hypertext summit”, and came to the conclusion it was dumb from almost every angle:
-
Every document had to be re-written in HTML with only links as an added value
-
The links cannot be contextual - because they MUST be the same for all users
-
Only the dumbest unidirectional links were supported (and no mechanism for dead link checking)
-
Completely static
-
Mangled the notion of SGML by adding style tags like *mixed in with semantics (style was supposed to be like CSS today)
-
Even HTTP was stupid*
Obviously we misjudged…
Last thought - Agile.
A lot of the language of the video is the same as the language of the modern Agile community, which I find interesting too. In a follow up, I’ll go into that.
https://www.grammarly.com/blog/engineering/running-lisp-in-production/
Running Lisp in Production
At Grammarly, the foundation of our business, our core grammar engine, is written in Common Lisp. It currently processes more than a thousand sentences per second, is horizontally scalable, and has reliably served in production for almost three years. We noticed that there are very few, if any, accounts of how to deploy Lisp software to modern cloud infrastructure, so we thought that it would be a good idea to share our experience. The Lisp runtime and programming environment provides several unique—albeit obscure—capabilities to support production systems (for the impatient, they are described in the final chapter).
Wut Lisp?!!

Contrary to popular opinion, Lisp is an incredibly practical language for building production systems. There are, in fact, many Lisp systems out there: When you search for an airline ticket on Hipmunk or take a Tube train in London, Lisp programs are being called.
Our Lisp services are conceptually a classical AI application that operates on huge piles of knowledge created by linguists and researchers. It’s mostly a CPU-bound program, and it is one of the biggest consumers of computing resources in our network.
We run these services on stock Linux images deployed to AWS. We use SBCL for production deployment and CCL on most of the developers’ machines. One of the nice things about Lisp is that you have an option of choosing from several mature implementations with different strengths and weaknesses: In our case, we optimized for processing speed on the server and for compilation speed in the dev environment (the reason this is critical for us is described in the later section).
A stranger in a strange land

At Grammarly, we use many programming languages for developing our services: In addition to JVM languages and JavaScript, we also develop in Erlang, Python, and Go. Proper service encapsulation enables us to use whatever language and platform makes the most sense. There is a cost to maintenance, but we value choice and freedom over rules and processes.
We also try to rely on simple language-agnostic infrastructure tools. This approach spares us a lot of trouble integrating this zoo of technologies in our platform. For instance, StatsD is a great example of an amazingly simple and useful service that is extremely easy to use. Another one is Graylog2; it provides a brilliant specification for logging, and although there was no ready-made library for working with it from CL, it was really easy to assemble from the building blocks already available in the Lisp ecosystem. This is all the code that was needed (and most of it is just “word-by-word” translation of the spec):
(defun graylog (message &key level backtrace file line-no)
(let ((msg (salza2:compress-data
(babel:string-to-octets
(json:encode-json-to-string #{
:version "1.0"
:facility "lisp"
:host *hostname*
:|short_message| message
:|full_message| backtrace
:timestamp (local-time:timestamp-to-unix (local-time:now))
:level level
:file file
:line line-no
})
:encoding :utf-8)
'salza2:zlib-compressor)))
(usocket:socket-send (usocket:socket-connect
*graylog-host* *graylog-port*
:protocol :datagram :element-type '(unsigned-byte 8))
msg (length msg))))
One of the common complaints about Lisp is that there are no libraries in the ecosystem. As you see, five libraries are used just in this example for such things as encoding, compression, getting Unix time, and socket connections.
Lisp libraries indeed exist, but like all library integrations, we have challenges with them as well. For instance, to plug into the Jenkins CI system, we had to use xUnit, and it was not so straightforward to find the spec for it. Fortunately, this obscure Stack Overflow question helped—we ended up having to build this into our own testing library should-test.
Another example is using HDF5 for machine learning models exchange: It took us some work to adapt the low-level HDF5-cffi library to our use case, but we had to spend much more time upgrading our AMIs to support the current version of the C library.
Another principle that we try to follow in Grammarly platform is maximal decoupling of different services to ensure horizontal scalability and operational independence. This way, we do not need to interact with databases in the critical paths in our core services. We do, however, use MySQL, Postgres, Redis, and Mongo, for internal storage, and we’ve successfully used CLSQL, postmodern, cl-redis, and cl-mongo to access them from the Lisp side.
We rely on Quicklisp for managing external dependencies and a simple system of bundling library source code with the project for our internal libraries or forks. The Quicklisp repository hosts more than a thousand Lisp libraries—not a mind-blowing number, but quite enough for covering all of our production needs.
For deployment into production, we use a universal stack: The application is tested and bundled by Jenkins, put on the servers by Rundeck, and run there as a regular Unix process by Upstart.
Overall, the problems we face with integrating a Lisp app into the cloud world are not radically different from the ones we encounter with many other technologies. If you want to use Lisp in production—and to experience the joy of writing Lisp code—there is no valid technical reason not to!
The hardest bug I’ve ever debugged

As ideal as this story is so far, it has not been all rainbows and unicorns.
We’ve built an esoteric application (even by Lisp standards), and in the process have hit some limits of our platform. One unexpected thing was heap exhaustion during compilation. We rely heavily on macros, and some of the largest ones expand into thousands of lines of low-level code. It turned out that the SBCL compiler implements a lot of optimizations that allow us to enjoy quite fast generated code, but some of them require exponential time and memory resources. Unfortunately, there’s no way to influence that by turning them off or tuning somehow. However, there exists a well-known general solution, call-with-* style, in which you trade off a little performance for better modularity (which turned out crucial for our use case) and debuggability.
Less surprising than compiler taming, we have spent some time with GC tuning to improve the latency and resource utilization in our system. SBCL provides a decent generational garbage collector, although the system is not nearly as sophisticated as in the JVM. We had to tune the generation sizes, and it turned out that the best option was to use an oversize heap: Our application consumes 2–4 gigabytes of memory but we run it with 25G heap size, which automatically results in a huge volume for the nursery. Yet another customization we had to make—a much less obvious one—was to run full GC programmatically every N minutes. With a large heap, we have noticed a gradual memory usage buildup over periods of tens of minutes, which resulted in spans of more time spent in GC and decreased application throughput. Our periodic GC approach got the system into a much more stable state with almost constant memory usage. On the left, you can see how an untuned system performs; on the right, the effect of periodic collection.
Of all these challenges, the worst bug I’ve ever seen was a network bug. As usual with such stories, it was not a bug in the application but a problem in the underlying platform (this time, SBCL). And, moreover, I was bitten by it twice in two different services. But the first time I couldn’t figure it out, so I had to develop a workaround.
As we were just beginning to run our service under substantial load in production, after some period of normal operation all of the servers would suddenly start to slow down and then would become unresponsive. After much investigation centering on our input data, we discovered that the problem was instead a race condition in low-level SBCL network code, specifically in the way the socket function getprotobyname, which is non-reentrant, was called. It was quite an unlikely race, so it manifested itself only in the high-load network service setup when this function was called tens of thousands of times. It knocked off one worker thread after another, eventually rendering the service comatose.
Here’s the fix we settled on; unfortunately, it can’t be used in a broader context as a library. (The bug was reported to SBCL maintainers, and there was a fix there as well, but we are still running with this hack, just to be sure :).
#+unix
(defun sb-bsd-sockets:get-protocol-by-name (name)
(case (mkeyw name)
(:tcp 6)
(:udp 17)))
Back to the future

Common Lisp systems implement a lot of the ideas of the venerable Lisp machines. One of the most prominent ones is the SLIME interactive environment. While the industry waits for LightTable and similar tools to mature, Lisp programmers have been silently and haughtily enjoying such capabilities with SLIME for many years. Witness the power of this fully armed and operational battle station in action.
But SLIME is not just a Lisp’s take on an IDE. Being a client-server application, it allows to run its back-end on the remote machine and connect to it from your local Emacs (or Vim, if you must, with SLIMV). Java programmers can think of JConsole, but here you’re not constrained by the predefined set of operations and can do any kind of introspection and changes you want. We could not have debugged the socket race condition without this functionality.
Furthermore, the remote console is not the only useful tool provided by SLIME. Like many IDEs, it has a jump-to-source function, but unlike Java or Python, I have SBCL’s source code on my machine, so I often consult the implementation’s sources, and this helps understand what’s going on much better. For the socket bug case, this was also an important part of the debugging process.
Finally, another super-useful introspection and debugging tool we use is Lisp’s TRACE facility. It has completely changed my approach to debugging—from tedious local stepping to exploring the bigger picture. It was also instrumental in nailing our nasty bug.
With trace, you define a function to trace, run the code, and Lisp prints all calls to that functions with arguments and all of its returns with results. It is somewhat similar to stacktrace, but you don’t get to see the whole stack and you dynamically get a stream of traces, which doesn’t stop the application. trace is like print on steroids; it allows you to quickly get into the inner workings of arbitrary complex code and monitor complicated flows. The only shortcoming is that you can’t trace macros.
Here’s a snippet of tracing I did just today to ensure that a JSON request to one of our services is properly formatted and returns an expected result:
0: (GET-DEPS
("you think that's bad, hehe, i remember once i had an old 100MHZ dell
unit i was using as a server in my room"))
1: (JSON:ENCODE-JSON-TO-STRING
#<HASH-TABLE :TEST EQL :COUNT 2 {1037DD9383}>)
2: (JSON:ENCODE-JSON-TO-STRING "action")
2: JSON:ENCODE-JSON-TO-STRING returned "\"action\""
2: (JSON:ENCODE-JSON-TO-STRING "sentences")
2: JSON:ENCODE-JSON-TO-STRING returned "\"sentences\""
1: JSON:ENCODE-JSON-TO-STRING returned
"{\"action\":\"deps\",\"sentences\":[\"you think that's bad,
hehe, i remember once i had an old 100MHZ dell unit i was using as a
server in my room\"]}"
0: GET-DEPS returned
((("nsubj" 1 0) ("ccomp" 9 1) ("nsubj" 3 2) ("ccomp" 1 3) ("acomp" 3 4)
("punct" 9 5) ("intj" 9 6) ("punct" 9 7) ("nsubj" 9 8) ("root" -1 9)
("advmod" 9 10) ("nsubj" 12 11) ("ccomp" 9 12) ("det" 17 13)
("amod" 17 14) ("nn" 16 15) ("nn" 17 16) ("dobj" 12 17)
("nsubj" 20 18) ("aux" 20 19) ("rcmod" 17 20) ("prep" 20 21)
("det" 23 22) ("pobj" 21 23) ("prep" 23 24)
("poss" 26 25) ("pobj" 24 26)))
((<you 0,3> <think 4,9> <that 10,14> <'s 14,16> <bad 17,20> <, 20,21>
<hehe 22,26> <, 26,27> <i 28,29> <remember 30,38> <once 39,43>
<i 44,45> <had 46,49> <an 50,52> <old 53,56> <100MHZ 57,63>
<dell 64,68> <unit 69,73> <i 74,75> <was 76,79> <using 80,85>
<as 86,88> <a 89,90> <server 91,97> <in 98,100> <my 101,103>
<room 104,108>))
So to debug our nasty socket bug, I had to dig deep into the SBCL network code and study the functions being called, then connect via SLIME to the failing server and try tracing one function after another. And when I got a call that didn’t return, that was it. Finally, looking at man to find out that this function isn’t re-entrant and encountering some references to that in the SBCL’s source code comments allowed me to verify this hypothesis.
That said, Lisp proved to be a remarkably reliable platform for one of our most critical projects. It is quite fit for the common requirements of modern cloud infrastructure, and although this stack is not very well-known and popular, it has its own strong points—you just have to learn how to use them. Not to mention the power of the Lisp approach to solving difficult problems—which is why we love it. But that’s a whole different story, for another time.